Programming Distributed Accelerator System with Code Generation Compiler
摘要&结论¶
Use distributed system composed of multiple accelerators for training and inference.
- three fundamental activities: computation, memory access, and communication
❌ these aspects are often optimized independently at different programming level
- difficult for these activities to coordinate with each other
✅ Using a high-level compiler(Triton-distributed) for programming distributed systems
- unify the programming of both computations and communications at the same level
- joint optimization among computation, memory access, and communication
Triton-distributed: an alternative approach for fine-grained computation-communication overlapping using compiler-assisted programming
- integrate communication primitives compliant with the OpenSHMEM standard into the compile
- enables programmers to utilize these primitives within a higher-level Python programming model
- enhances the open-source Triton framework by extending a rich set of communication primitives fully compliant with OpenSHMEM specifications(enable communication across both single-node and multi-node GPU clusters)
- show how to use overlapping techniques to hide latency (single/multi-node scenarios)
- demonstrate how to design kernels to overlap various activities based on the primitives: computation, memory access, intra/inter-node communication
- developers only focus on adding communication logic
优势:生成代码性能好,开发难度低
- unify the programming languages for distributed kernels and computational kernels
已有计算通信重叠优化途径:
- 算子切小:创造没有依赖的计算、通信算子

- 问题:
- 小算子之间需插入同步,而同步需要CPU介入
- 完整算子切开后,延迟总和大于原算子
- 问题:
- 在GPU上进行stream同步:在算子内部正确的位置正确的时机写出信号或者等待信号
引言¶
Efficient deployment of AI models depends on the co-optimization of underlying hardware and software
- software level: map large-scale computations and parameters onto hardware
- hardware: single device -> multi-accelerator systems
‼️ Distributed programming is notoriously difficult
- 要么只适用于CPU集群,要么在加速器上性能一般
- 算法开发(Python)和算子实现(CUDA/C++)的割裂
✅ Research on compiler optimization for single chip has almost converged, compiler research has entered a distributed era.
For LLMs, the key requirement for distributed optimization becomes computation-communication overlapping.
- as cluster number scales exponentially, overlapping computation with communication becomes vital
- ⚠️ The ability to overlap computation with communication has exceeded the scope of existing compiler
Compilation stack:
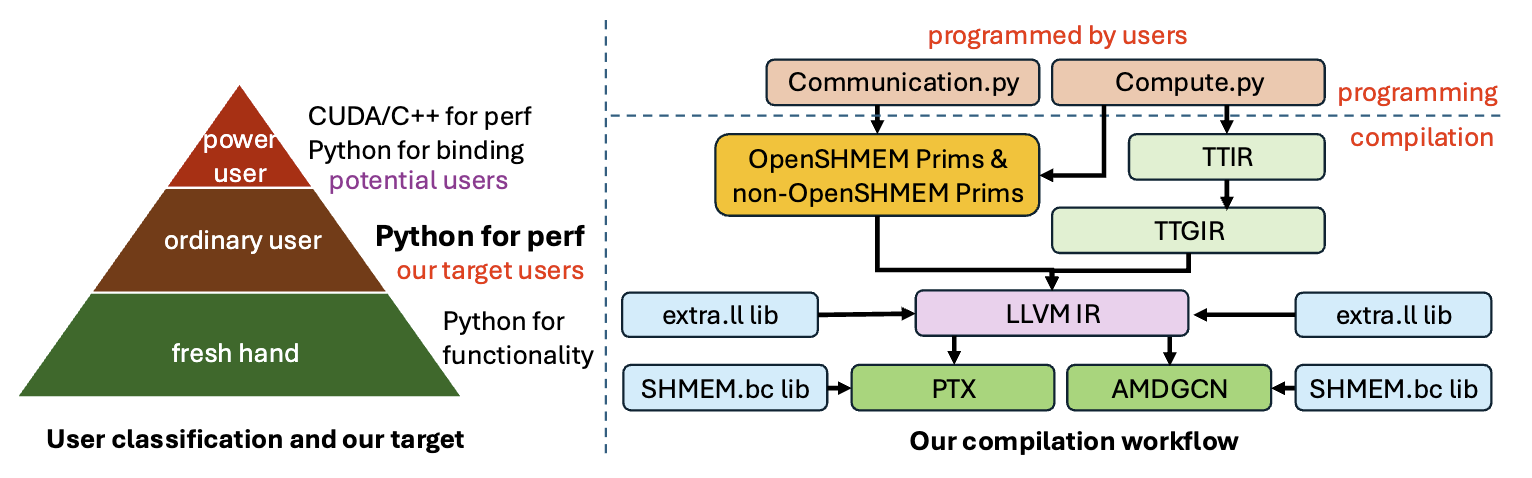
- program communication and computation parts separately in Python
编程模型¶
MPMD¶
rank
- rank 是逻辑概念,类似于进程,用于唯一标识一个通信参与者
- 对GPU而言,常见的做法是1 device ~ 1 rank
- rank VS node: node是物理概念,指代机器(如一台服务器),对于单机八卡集群而言,1 node ~ 8 device, 通常可以起8个rank
- 对CPU而言,每个rank可以灵活调度到不同的CPU core上,rank数可以比core多
Symmetric Memory:
- Each rank allocates a memory buffer in the global scope with the same size
- separate address space, no uniform virtual address space
- remote memory buffers cannot be accessed directly via pointers
- specific primitives are required to perform remote data transfer
Signal Exchange:
- signal: a data object that resides in symmetric memory
- rank间操作利用signal互相通信以维护一致性(可在rank内/rank间交换)
- operations: setting the value of a signal, increasing the value of a signal, checking the value of a signal, and performing a spin-lock on a given signal
Async-Task:
- data transfer and computation are treated as asynchronous tasks that run in parallel
- Async-tasks can be synchronized through signals
- even on the same rank, the operations are asynchronous
- implementation:
- GPU: multi-streaming(runtime task queues to launch different tasks simultaneously) and multi-threading(leverages parallel hardware units)
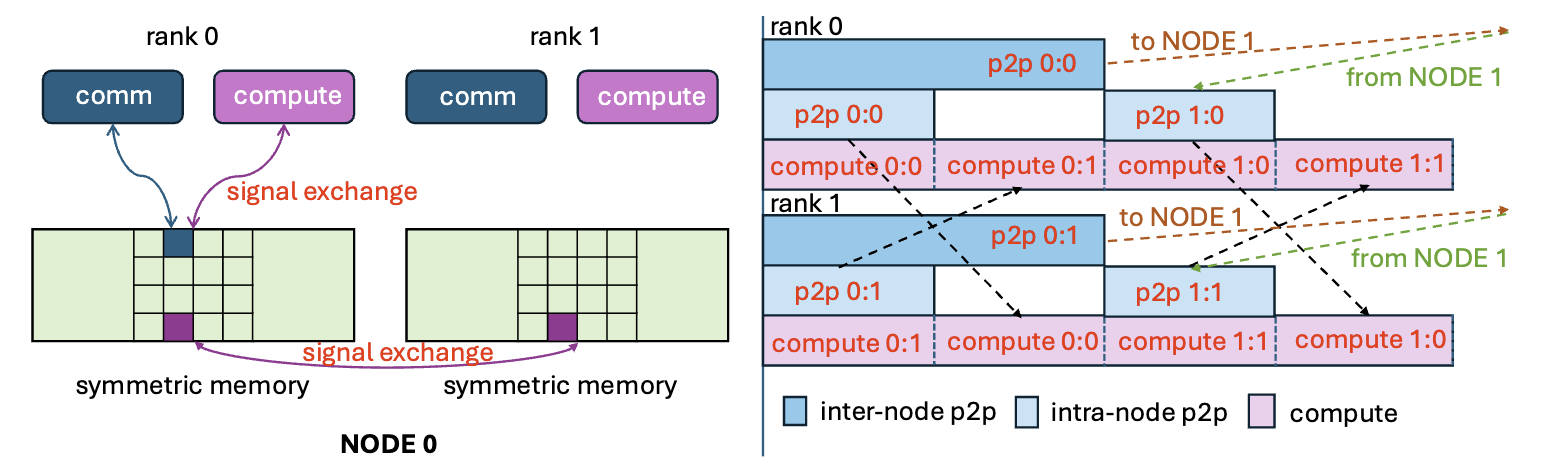
- 通信、计算被分散在不同的SM上
- 调度目标:计算不能等通信
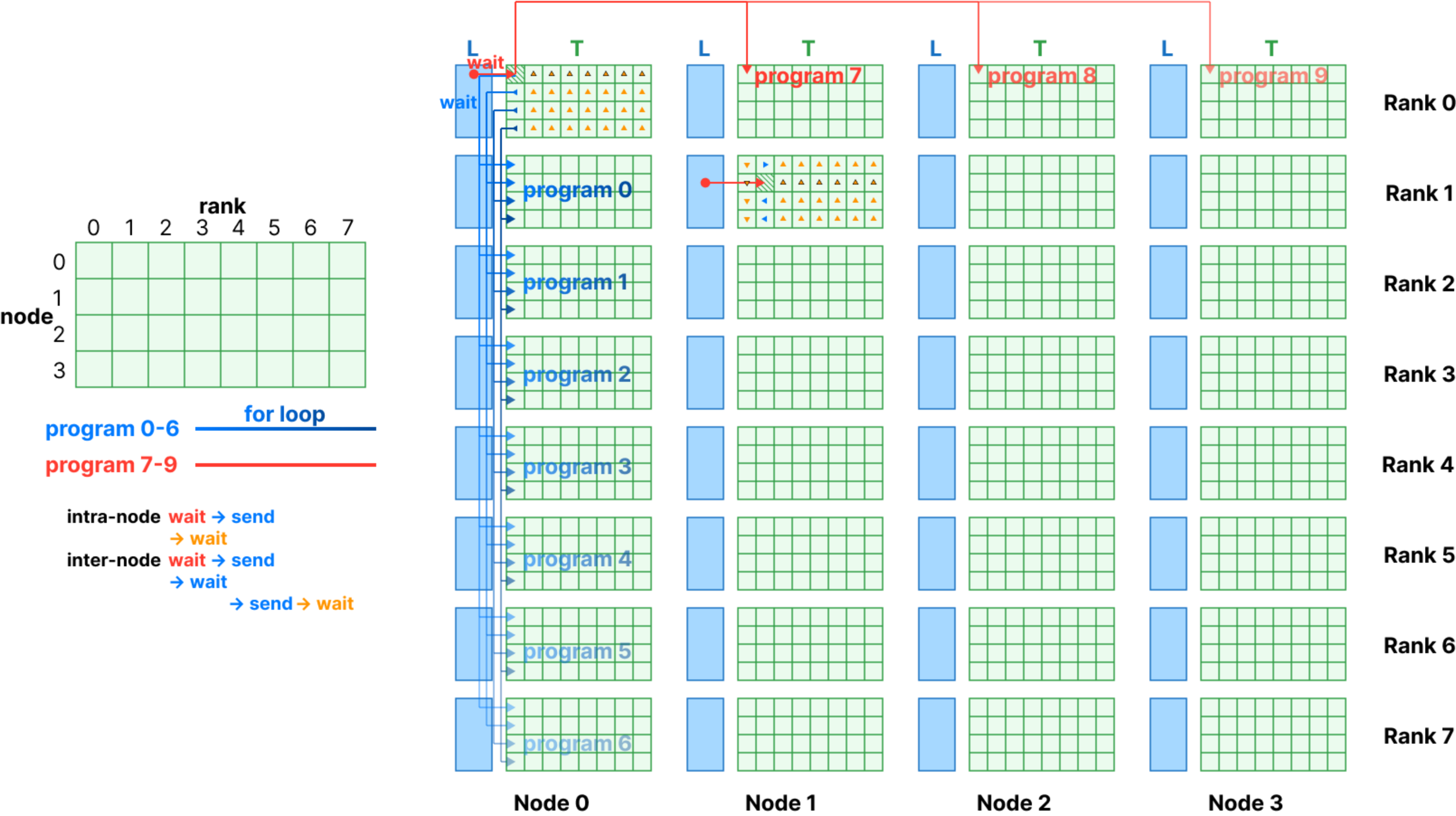
- rank 0, 1并行下发3个任务,对于rank 0而言,同时进行node间通信(NODE 0, rank 0 -> NODE 1, 跨NODE通信时间长), node内通信(NODE 0, rank 0 -> Node 0, rank 1), 计算(NODE 0, rank 0数据)
通信原语¶
‼️ For a distributed system, the essence of designing primitives is to model communication patterns effectively
- depends on interconnection topology and bandwidth
- 当下主流GPU均基于OpenSHMEM标准,故对其该标准进行原语设计
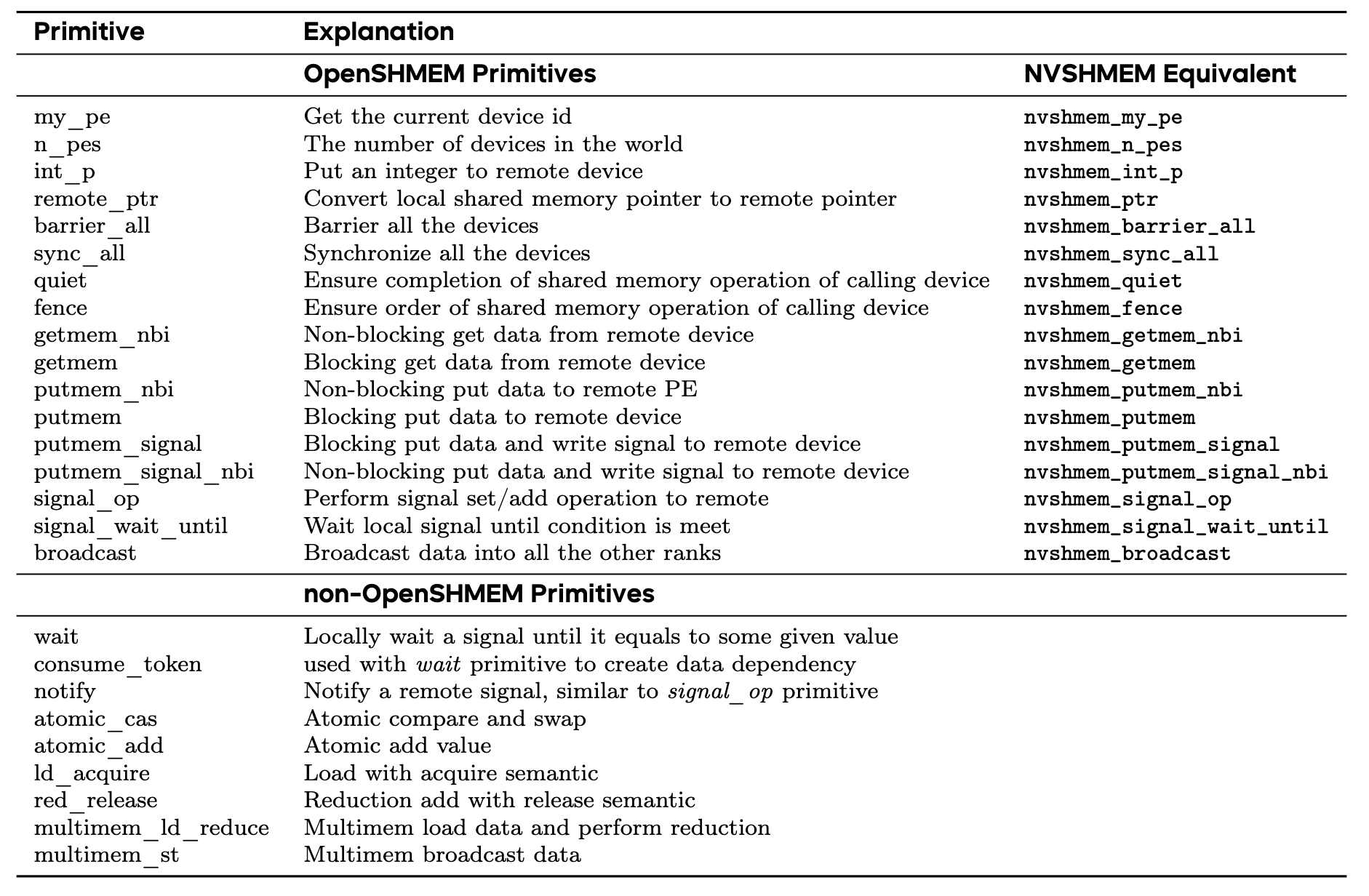
- 非OpenSHMEM原语:出于优化目的而设计
AllGather
- 所有参与进程(或设备)各自拥有一部分数据;
- 执行 AllGather 后,每个进程都收集到了所有其他进程的数据。
Inter-node Overlapping AllGather GEMM
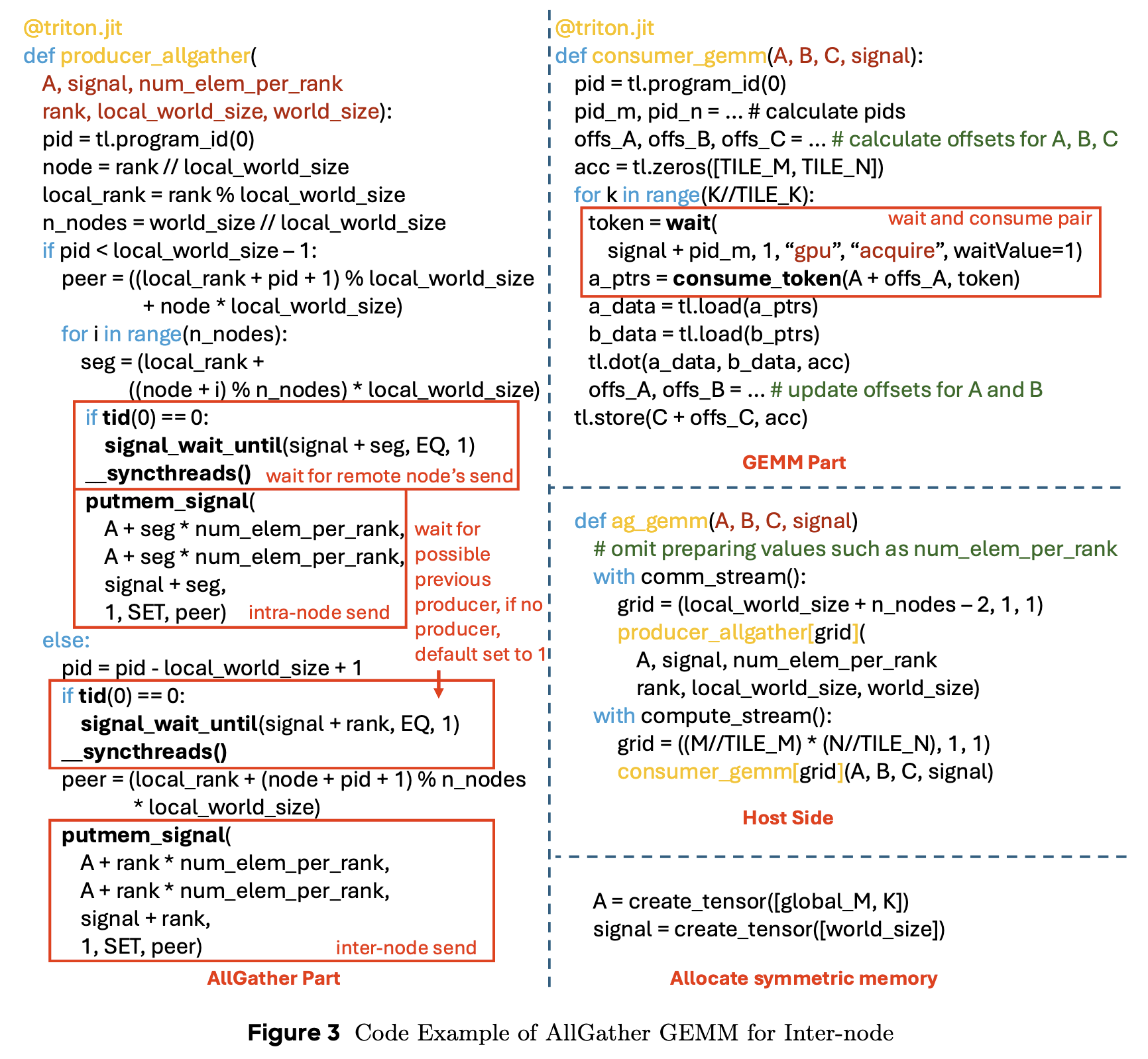
- 组成:communication part, the computation part, and the host side
- communication part:
- assign different tasks to different threadblock: intra-node dispatch, inter-node data transfer
- two groups of threadblocks run in parallel to overlap inter-node data transfer and intra-node data transfer
- computation part: reuse Triton’s original GEMM implementation
- wait: produces a token related to a signal
- consume_token: consumes the token and creates data dependency between the token and the following data load
- different tiles run in parallel, each tile waits for its own signal, overlapping its dependent communication and other tiles’ computation
- host-side: allocates symmetric memory, launches the communication part and the computation part on different streams
- communication part:
重叠算子优化¶
one-sided
All communication operations are programmed from the perspective of a single rank, which is different from collective communication programming, where communication is programmed against all ranks.
优化方法¶
- Intra-Node Swizzle
- Inter-Node Swizzle
- Inter-NUMA Swizzle
- Copy Engine
- High-BW Link
- Network Communication
- PCIe Communication
- OpenSHMEM Support
- Low-latency Protocol
- Multimem Feature
- Fusion
- Code Generation
- Nvidia/AMD
Communication type
- AllGather: 收集所有进程的数据并发送给所有进程
- Before: P0: A, P1: B, P2: C, P3: D
- After: P0 /1 /2 /3: [A, B, C, D]
- ReduceScatter: 各个进程先对相同索引的数据进行规约,然后每个进程获得规约结果的一部分
- Before: P0: [a0, a1, a2, a3], P1: [b0, b1, b2, b3], P2: [c0, c1, c2, c3], P3: [d0, d1, d2, d3]
- After: P0: a0 + b0 + c0 + d0, P1: a1 + b1 + c1 + d1, P2: a2 + b2 + c2 + d2, P3: a3 + b3 + c3 + d3
- AllToAll: 每个进程都从所有其他进程那里收到了一段数据
- Before: P0: [A0, A1, A2, A3], P1: [B0, B1, B2, B3], P2: [C0, C1, C2, C3], P3: [D0, D1, D2, D3]
- After: P0: [A0, B0, C0, D0], P1: [A1, B1, C1, D1], P2: [A2, B2, C2, D2], P3: [A3, B3, C3, D3]
Intra-node AllGather with Copy Engine¶
Copy Engine: a dedicated DMA engine in GPU for data transfer between devices
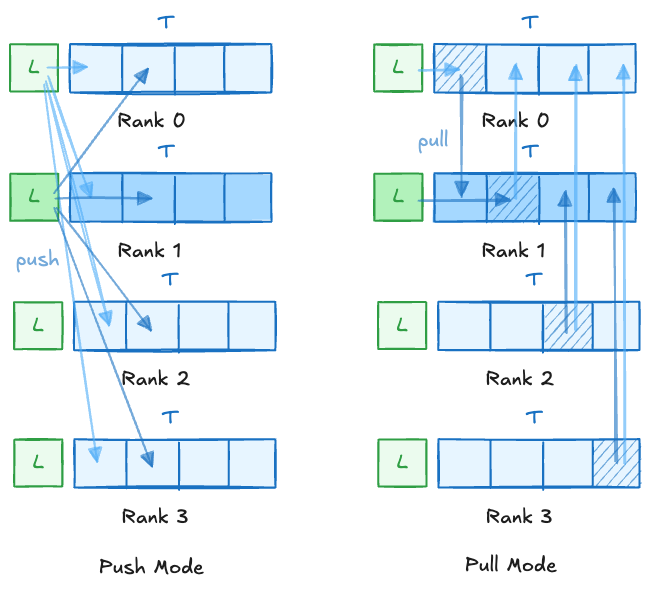
one-sided communication:
- push mode: can omit one synchronization operation but the data arrival order cannot be controlled
- 每个rank主动把自己的数据push到其它rank中
- push过去后,通知远端的数据已经就绪
- pull mode: need an additional synchronization but the data arrival order can be controlled
- 每个rank先主动把自己的数据放到对称缓冲区中的对应位置,并同步,确保所有rank都已完成放置
- 每个rank主动去pull别的rank中的数据
- pull过来后,通知本地的数据已经就绪


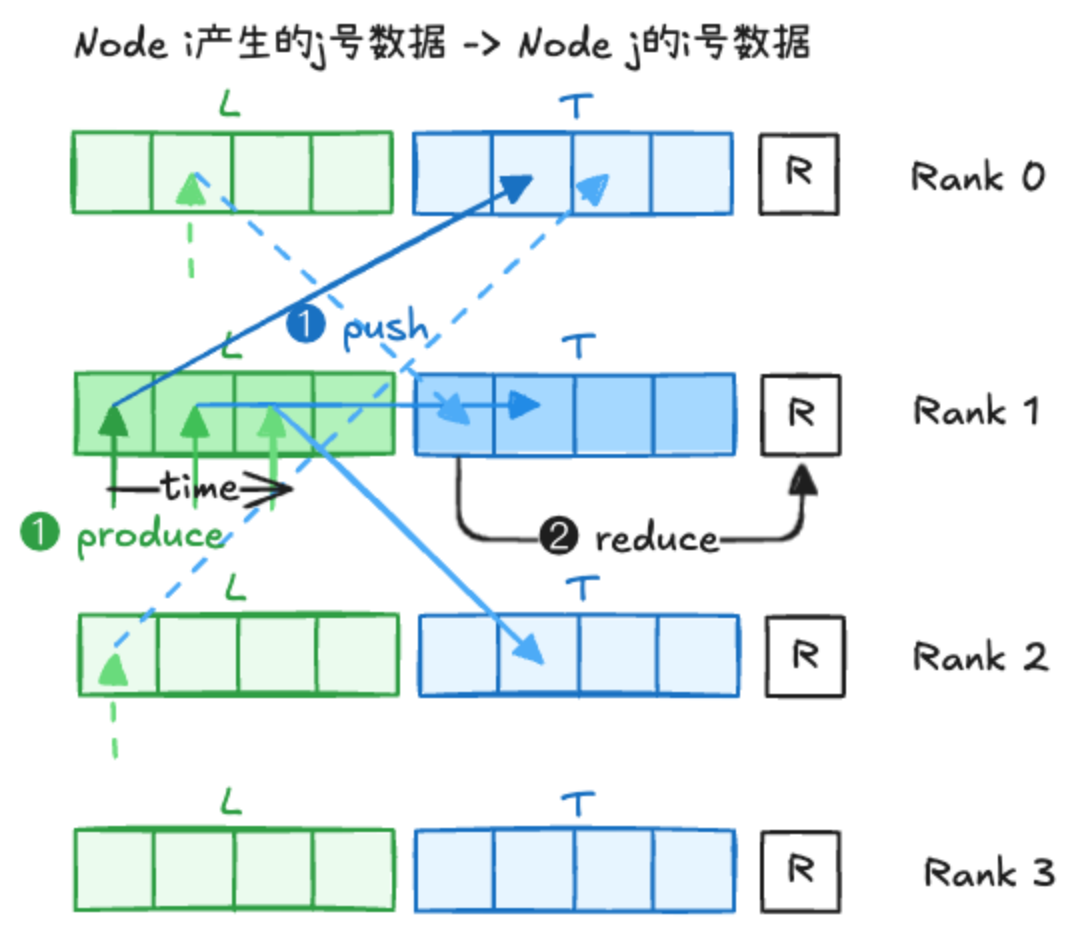
ReduceScatter with Copy Engine¶
ReduceScatter can also be implemented in push or pull mode.
One-sided ReduceScatter is composed of two parallel parts
- local data shard is pushed to all the other ranks after the producer generates one tile of data
- local reduction is done and produces the final output

Inter-node AllGather with Low-latency Protocol and Multimem Feature¶
核心: overlapping the inter-node data transfer and the intra-node data transfer
- processing delay and queuing delay are not critical
- main overhead of communication comes from propagation delay
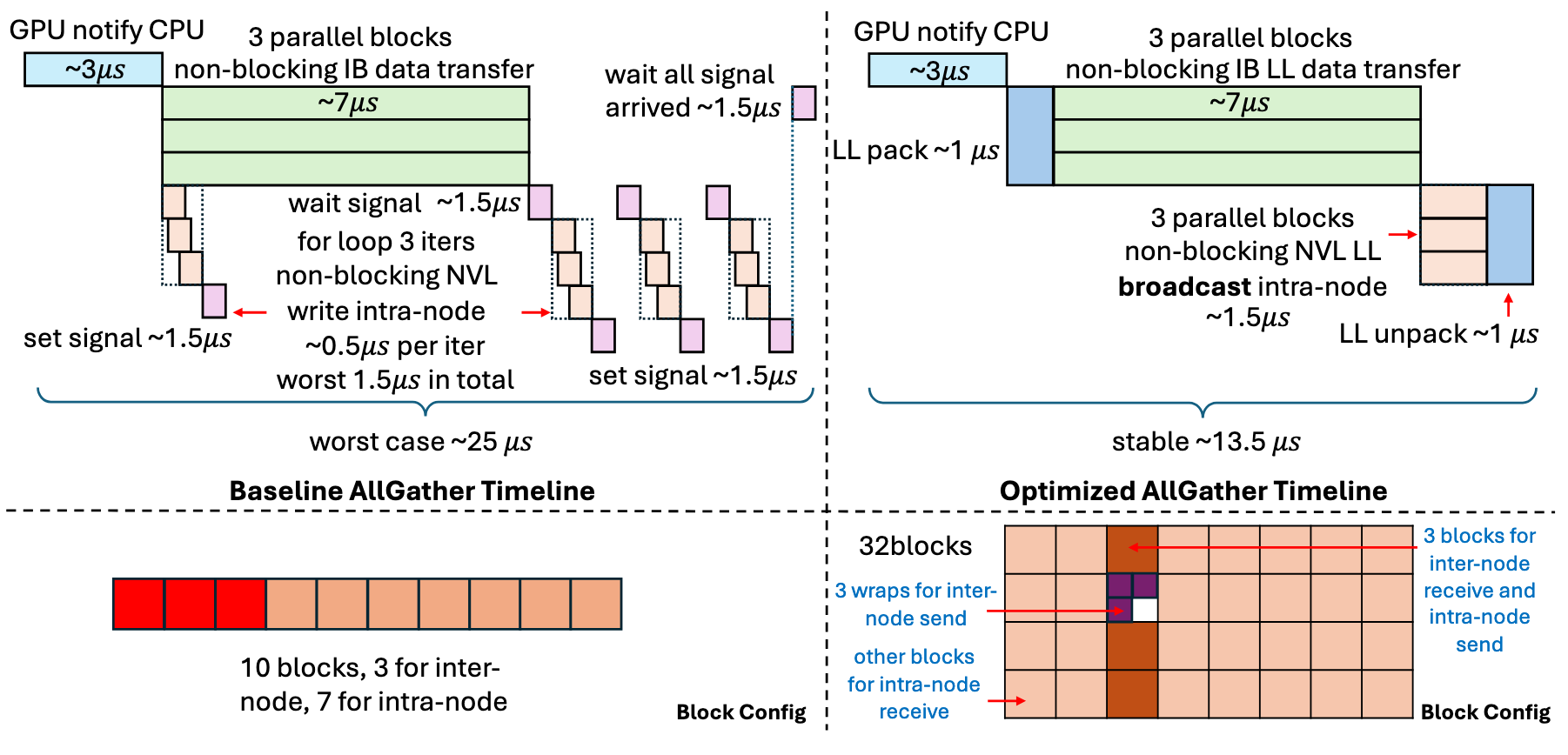
❌ Overlap through assigning asyc-tasks
- relies on loops to do data transfer: data transfer operations are not launched at the same time
- skew among the data transmission operations sent to different ranks
- the amount of transmitted data is very small, in the worst-case, the result of the skew is similar to sending data one by one
- each P2P data transfer requires a pair of signal operations (set signal and wait signal), causing additional overhead
multimem_st primitive
NVLink broadcast: store the same data to all the other ranks within one node(~1.5μs)
- 所以要区分inter/intra-node
low-latency protocol(LL)
LL protocol: relies on hardware feature of Nvidia GPU that 8 bytes data store/load is atomic across ranks
- LL protocol 基于GPU提供的不同rank对8字节共享数据的原子访问机制,相当于一种同步资源
- LL protocol 能降低延迟的核心在于==并发处理请求==,而不再是一个一个地串行处理请求
- LL protocol 利用这一同步资源,实现并发请求对共享数据访问的管理;如果数据是串行处理的,就不需要做并发管理了
⚠️ LL protocol is fast but doubles the message size (due to flags in message), which is suitable for small message scenarios but not for large message size
LL128 protocol: relies on the hardware feature of NVLink
✅ Use non-OpenSHMEM primitives(multimem PTX instruction) achieve intra-node broadcast and use low-latency protocol (LL) for inter-node data transfer

BLOCK_ID: current thread block index- 当前rank上每个负责通信的block的id, 每个block负责与一个rank进行通信(
WORLD_SIZEthread blocks)
- 当前rank上每个负责通信的block的id, 每个block负责与一个rank进行通信(
LOCAL_WORLD_SIZE: the number of ranks in one nodeLOCAL_RANK: the rank index of the current deviceNODE_ID: the node index that the current device belongs toN_NODES: the number of nodes in totalWORLD_SIZE: the number of ranks from all the nodes in totalrecv_LL_pack: perform LL receive operation without decoupling data from flagsrecv_LL_unpack: performs LL receive operation and separates the data from the flags- Block configuration:
- total:
WORLD_SIZEthread blocks - 1 for inter-node data send and local data receive
N_NODE-1warp for inter-node data send
N_NODE-1for inter-node data receive and intra-node data send- the other blocks are responsible for intra-rank receive
- total:
为什么使用warp进行跨node通信?
- warp 原生支持 NVSHMEM warp‑level non‑blocking API,硬件上并行度最高、延迟最低
- 每个
warp一次指令就能把一个大块发到对应节点的ll_buffer,减少线程同步和指令数。
@triton.jit
def _forward_push_2d_ll_multimem_kernel(
symm_ptr,
bytes_per_rank,
symm_ll_buffer,
nnodes: tl.constexpr,
world_size: tl.constexpr,
rank,
signal_target,
):
"""
pack_ll and nvshmem_putmem_nbi, then recv_ll and multimem.st
"""
local_world_size = world_size // nnodes
local_rank = rank % local_world_size
nid = rank // local_world_size
pid = tl.program_id(0)
peer_nid = pid // local_world_size
peer_local_rank = pid % local_world_size
num_ints = bytes_per_rank // 4
thread_idx = tid(axis=0)
ll_buffer_int8 = tl.cast(symm_ll_buffer, tl.pointer_type(tl.int8))
symm_ptr = tl.cast(symm_ptr, tl.pointer_type(tl.int8))
if peer_local_rank == local_rank:
if nid != peer_nid:
segment = peer_nid * local_world_size + local_rank
_recv_ll_and_multimem_st_ll_block(
ll_buffer_int8 + segment * bytes_per_rank * 2,
ll_buffer_int8 + segment * bytes_per_rank * 2,
num_ints,
signal_target,
) # magic number here
_recv_ll_block(
symm_ptr + segment * bytes_per_rank,
ll_buffer_int8 + segment * bytes_per_rank * 2,
num_ints,
signal_target,
) # magic number here
else: # already has data. pack only
_pack_ll_block(
ll_buffer_int8 + rank * bytes_per_rank * 2,
symm_ptr + rank * bytes_per_rank,
num_ints,
signal_target,
2048,
) # magic number here
__syncthreads()
wid = thread_idx // 32
# send
if wid < nnodes and wid != nid:
peer_to = wid * local_world_size + local_rank
libshmem_device.putmem_nbi_warp(
ll_buffer_int8 + rank * bytes_per_rank * 2,
ll_buffer_int8 + rank * bytes_per_rank * 2,
bytes_per_rank * 2,
peer_to,
) # write and tell peer remote that remote copy is done
segment = peer_nid * local_world_size + local_rank
broadcast_naive_block(
ll_buffer_int8 + segment * bytes_per_rank * 2,
ll_buffer_int8 + segment * bytes_per_rank * 2,
bytes_per_rank * 2,
)
else:
segment_recv_local = peer_nid * local_world_size + peer_local_rank
_recv_ll_block(
symm_ptr + segment_recv_local * bytes_per_rank,
ll_buffer_int8 + segment_recv_local * bytes_per_rank * 2,
num_ints,
signal_target,
) # magic number here
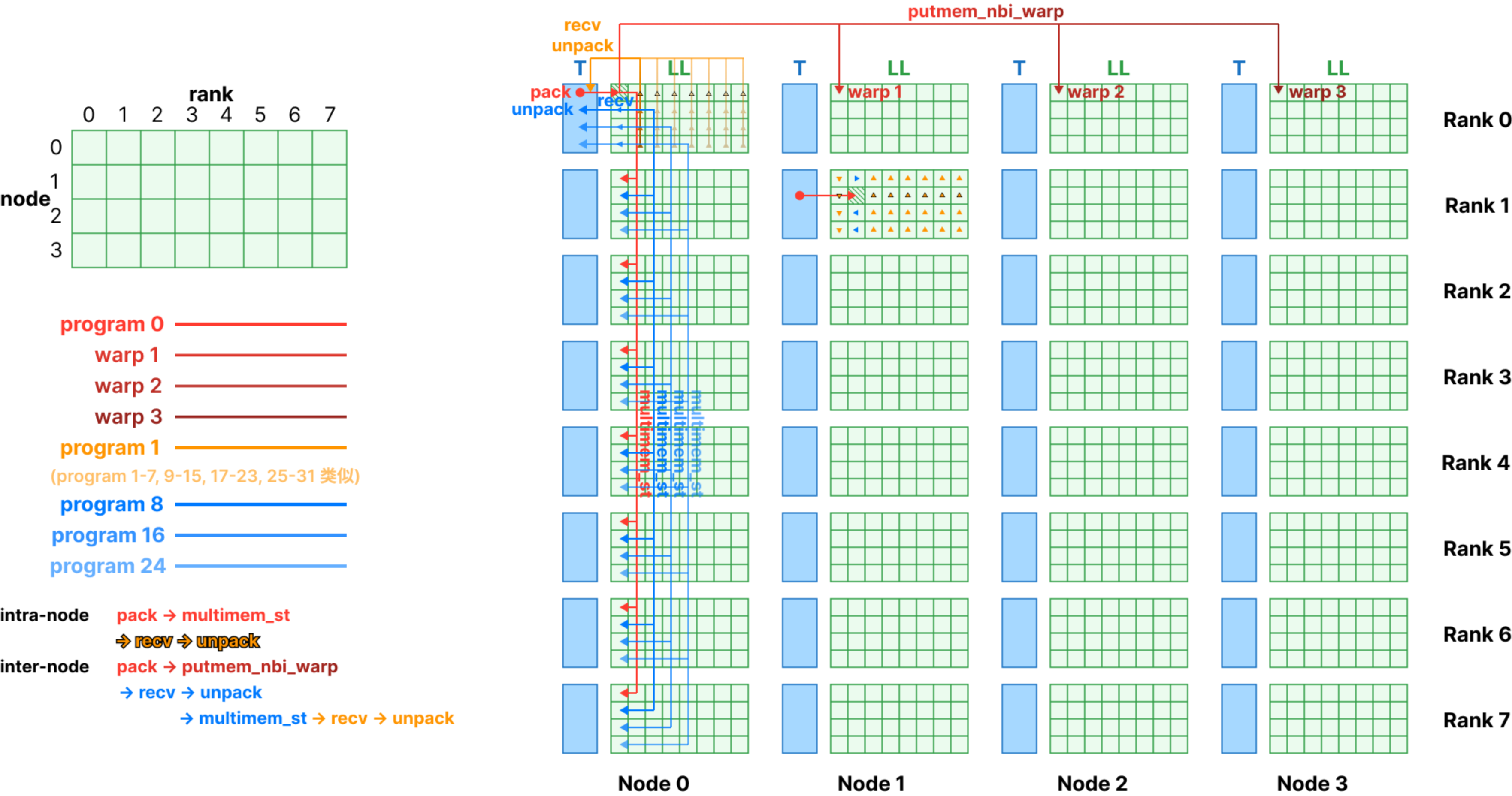
对rank 0:
| pid | 对应代码 | 职责 |
|---|---|---|
| 0 | line 11-18 | a) r0.T[0] -pack-> r0.LL[0]----sync----b) warp 1-3: r0.LL[0] -send-> r[8,16,24].LL[0]c) r0.LL[0] -broadcast-> r[1-7].LL[0] |
| 1-79-15 17-2325-31 | line 21-22 | let peer := 1-7,9-15,17-23,25-31a) wait for r[peer].LL[0] sent to r0.LL[peer](其中r[1,9,17,25]的数据由r1广播而来,以此类推)b) r0.LL[peer]-unpack->r0.T[peer] |
| 8,16,24 | line 6-9 | let peer := 8,16,24a) wait for r[peer].LL[0] sent to r0.LL[peer]b) r0.LL[peer]-broadcast->r[1-7].LL[peer]c) r0.LL[peer]-unpack->r0.T[peer] |
Inter-node ReduceScatter with Heterogeneous Communication¶
three stages:
- intra-node scatter
- local reduction
- local reduction operation requires SM resources
- inter-node P2P communication
✅ aim: maximize bandwidth while minimizing resource usage to ensure little affect on computation
- overlapping strategy for intra-node and inter-node communications: schedule the intra-node scatter on one stream, while the local reduction and P2P communication are assigned to another stream
- SM configuration:
- scatter operation: completed by the copy engine and does not require SM
- P2P communication: only requires 1 SM
- the number of SMs for local reduction is the minimum required value calculated based on hardware specifications
- 核心:两个stream互相掩藏
- scatter 时间 = 计算时间 + P2P 通信时间
- ∴ 计算时间 = scatter 时间 - P2P 通信时间
- 这样在第一次 scatter 冷启动后,计算、通信能与第二次 scatter 相重叠


P2P_send: inter-node P2P communication
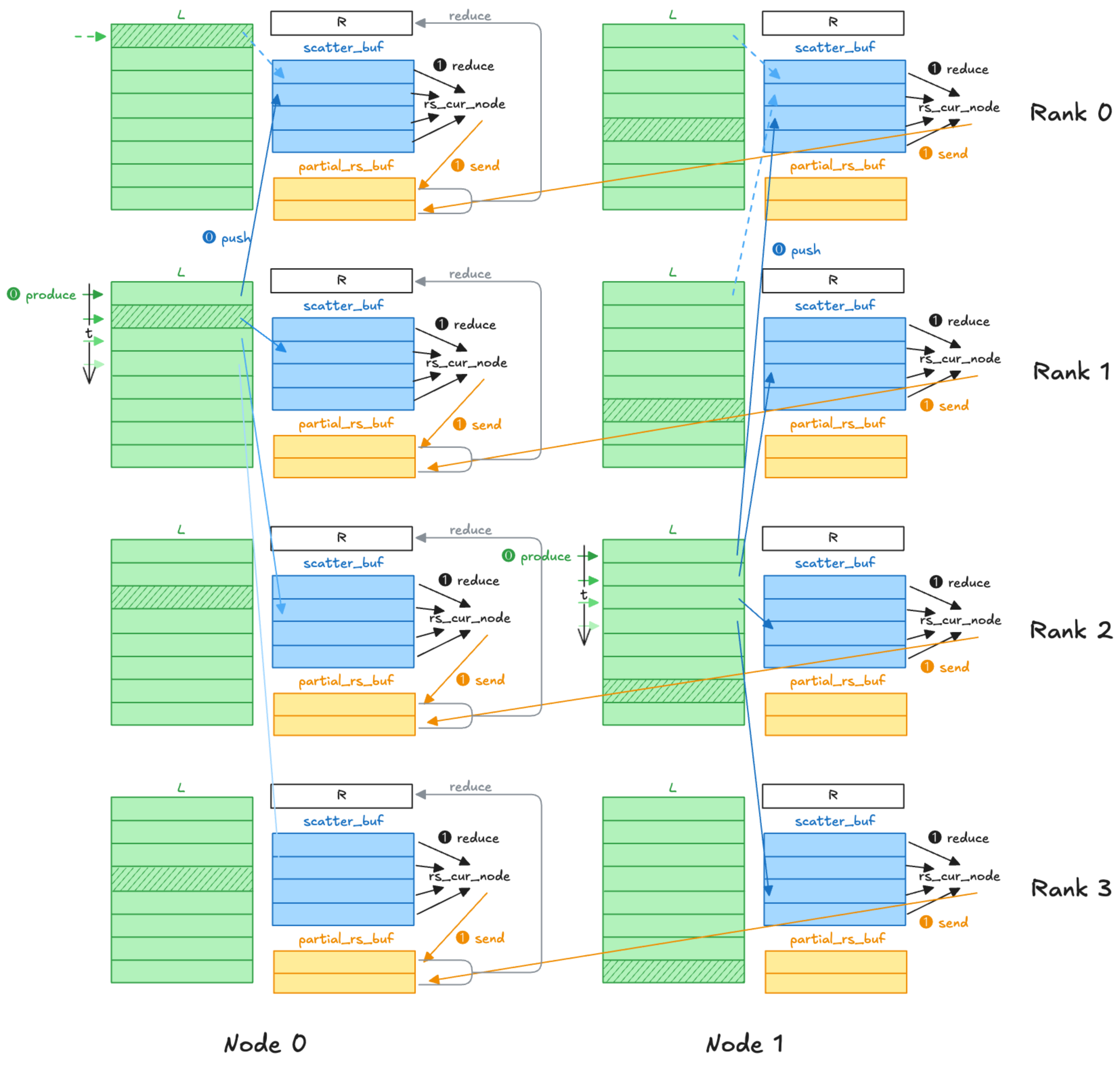
- 第一轮,所有node为node 0 产出部分和数据;规约后,发送给node 0的对应buffer
- 随后以此类推,每一轮为对应的node生产数据
Optimized Communication Kernels on AMD GPUs and more Platforms¶
AMD VS NVIDIA
通信机制:
- NVIDIA通信支持异步,即通信可交由部分SM执行,只需在SM内部同步即可
- 故NVIDIA的通信、计算算子之间可做overlap
- AMD只支持同步通信,发起通信后会阻塞整个GPU
- 故AMD的通信只能在算子内做overlap(通信时不可计算)
网络拓扑:
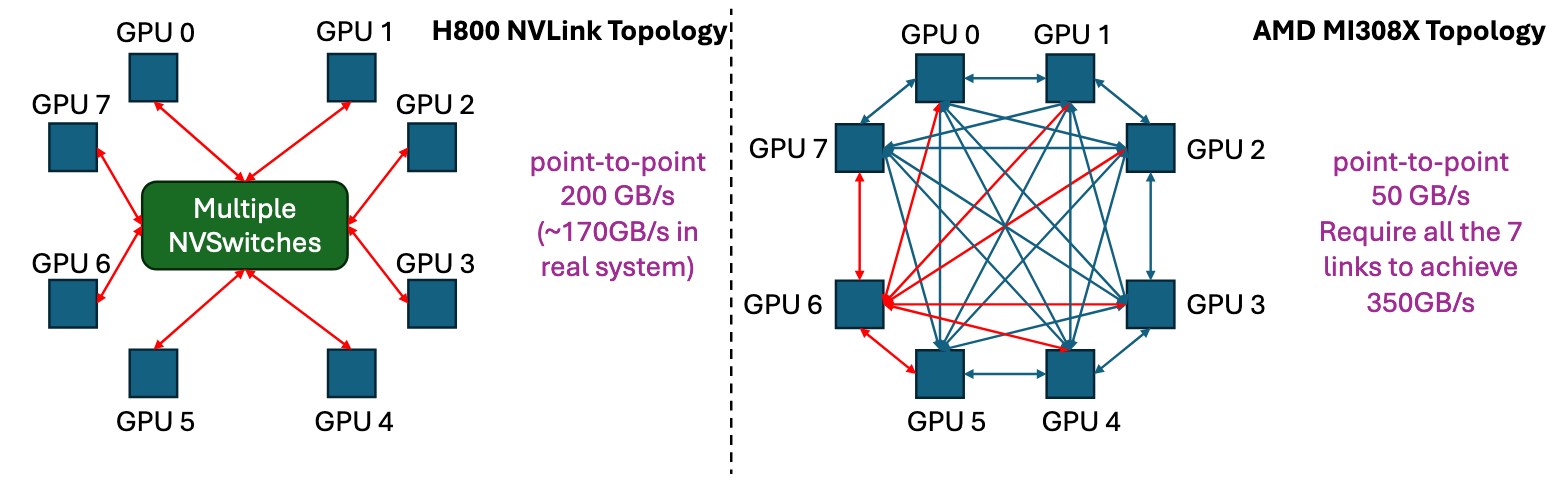
| 场景 | 区别 |
|---|---|
| Intra-node AllGather | NVIDIA: 由一个通信program逐个下发搬运任务,由NVSwitch负责任务调度AMD: 多个stream同时下发搬运任务以最大化带宽利用; 使用专门的传输任务下发搬运完成的信号, 防止通信API对计算的干扰 |
| Intra-node ReduceScatter | NVIDIA: 通信program等待计算program完成数据的produceAMD: 将producer和scatter融合, 将计算完成后的数据直接存到远端, 然后再执行barrier_all并reduce, 防止通信对计算造成影响 |
硬件适配要求: 支持硬件模型的3条假设
- Symmetric memory allocation and access
- Signal exchange, including signal setting, increasing, checking, and spin-locks
- Async-tasks, allowing to map specialized tasks spatially to different hardware units
Overlapping Computation with Swizzling Optimization¶
目的: optimizations for overlapping the computation part
Swizzle
Efficient GPU kernels, either Nvidia or AMD GPU, both rely on tiling to exploit parallelism and locality. And there is a tile mapping logic, from a thread block index to a tile coordinate. By controlling the order of tiles, we can both improve cache utilization (e.g., L2 cache) and communication efficiency (by reducing the critical path). The optimization that controls the order of tiles is called swizzling.
设计要点: the tile swizzle order in computation kernels align with the communication tiles
- avoid potential memory contention
- minimize tile data transfer time
Intra-node AllGather GEMM Swizzle¶
NVIDIA:
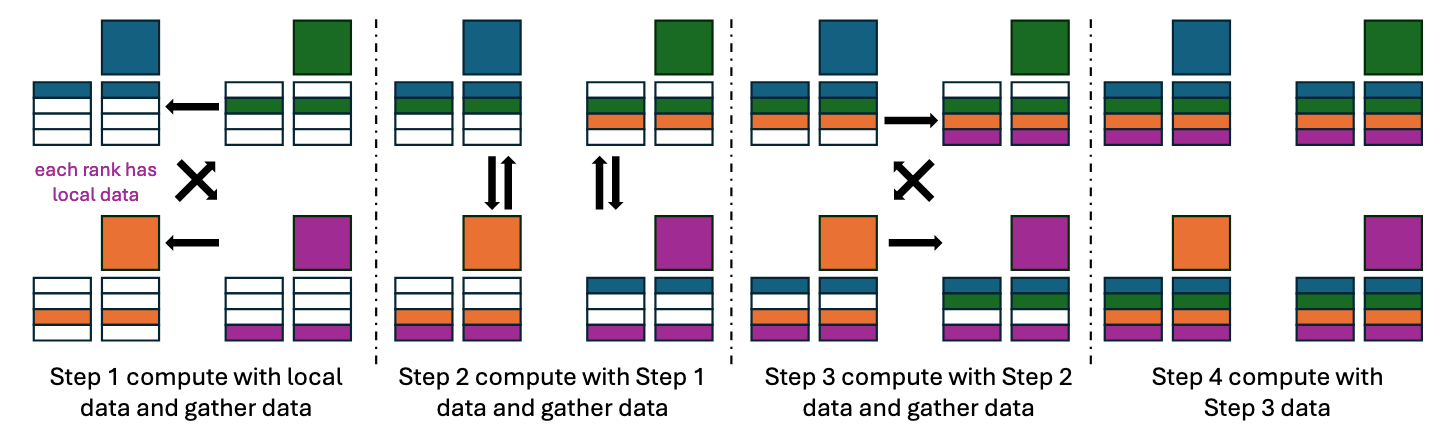
- 初始时,每个rank处理本地数据
- 每次获取一个来自不同rank的数据
AMD:
❌ 按照NVIDIA的方案,每次只能利用每个GPU相连的一条链路的带宽; 故每个GPU每次需要从其他所有GPU处接收数据
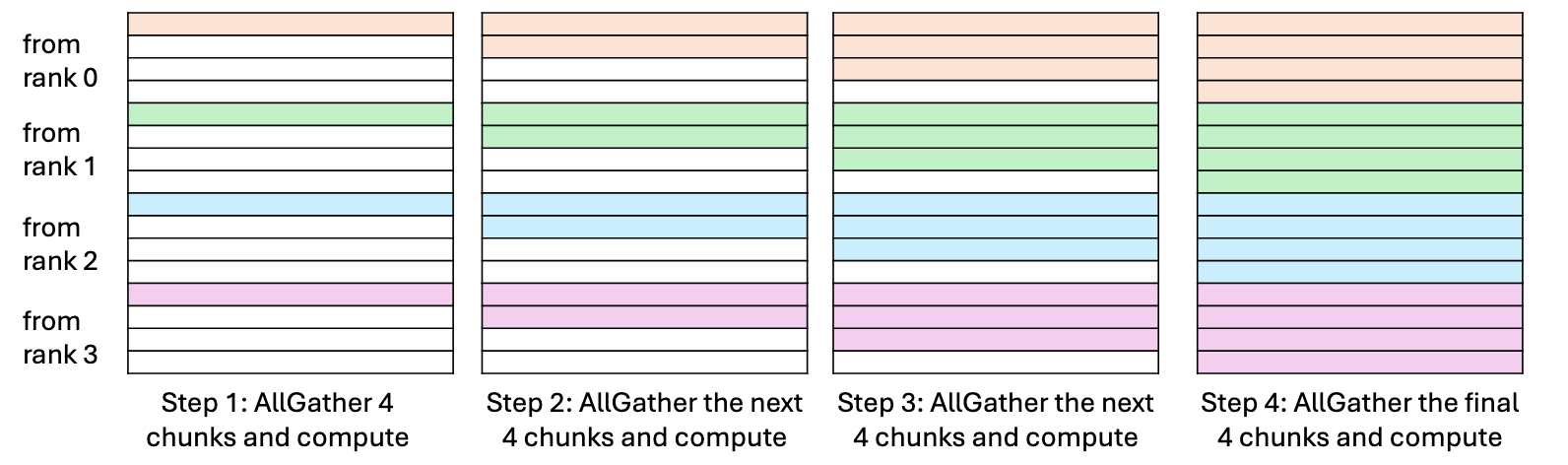
- 每次每rank都从其他所有rank处收到数据
- 以rank 0为例,第一次从所有rank收到所有rank的第一块数据,第二次收到所有rank的第二块数据,以此类推
Inter-node GEMM ReduceScatter Swizzle¶
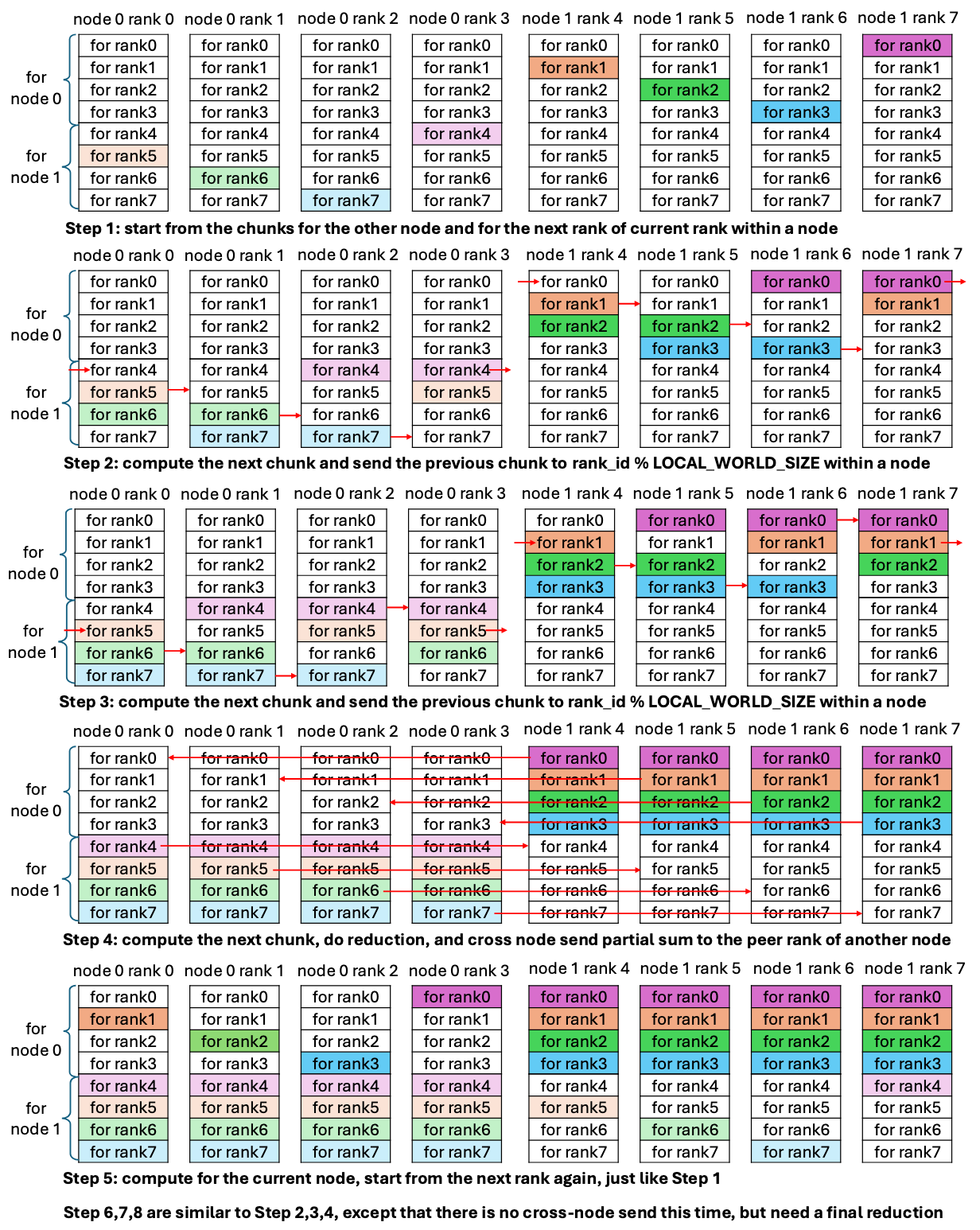
思想:
- Intra-node scatter 阶段:
- 将local copy调整到最后一次
- 从local rank对应的下一个数据开始发送
- 数据发送的具体顺序无所谓
- 以2 node, 4 rank per node为例,每次每rank发一个数据,共4个数据,而每个rank要接收4个数据,共需接收16个数据,故需4轮数据发送才能完成reduce操作
- 现在,第一次
rank 0 -> rank 1,rank 1 -> rank 2,rank 2-> rank 3,rank 3 -> rank 0, 每个rank在一轮发送后都能拿到1个数据,这样最后一轮为本地copy, 相当于总时间为\(3t_\text{intra copy}+t_\text{local copy}\), 而swizzle前的总时间是\(4t_\text{intra copy}\)
- Inter-node P2P 阶段:
- 将本地数据发送调整到最后一次
- 以2 node为例,每次每node发送一个数据,共2个数据,而每个node要接收2个数据,共需接收4个数据,故需2轮发送才能完成最终的reduce
- 现在,第一次
node 0 -> node 1,node 1 -> node 0, 最后一次就是本地发送了
- 将本地数据发送调整到最后一次
综合上述两点,计算顺序为:
- node 0从node 1需要的数据开始计算,且每个rank给它后一个rank发送数据
- 故对于 node 0 而言,rank 0 的
scatter_buf原先需接收 rank 0(node 0)/rank 4(node 1) 的数据,先考虑为 node 1 产出数据, 即选择 rank 4 的数据(rank 4的数据对rank 0而言是需要进行local copy的数据), 再考虑intra错位, 即选择 rank 5 的数据(local rank对应的下一个数据),发送至rank 1- 第二次,rank 0发送rank 6的数据给rank 2, 以此类推
- 而node 1在给node 0产出数据,考虑intra偏移后,rank 4先发送rank 1的数据给rank 5
- 故对于 node 0 而言,rank 0 的
Code Generation Optimization with Auto-Tuning and Resource Partition¶
Single device tuner: 依次试验每个参数配置的性能
❌ 不适用与通信算子: 通信算子涉及卡间同步操作,若每个算子独立调优,多次执行会破坏原有的同步逻辑
✅ 将整个重叠算子当作一个完整算子进行调优,每次每个算子只执行一遍
实验¶
benchmark: PyTorch + NCCL, FLUX(CUTLASS)
场景:
- Intra-node Kernel Performance on Nvidia GPUs
- AllGather GEMM
- GEMM ReduceScatter
- AllGather MoE
- MoE ReduceScatter
- Inter-node Kernel Performance on Nvidia GPUs
- AllGather GEMM
- GEMM ReduceScatter
- AllGather MoE and MoE ReduceScatter
- Distributed Flash Decoding
- Low-latency AllGather(PCIe)
- Low-latency AllToAll
- For expert-parallel MoE, AllToAll is mainly used for tokens communication among experts
- Intra-node Kernel Performance on AMD GPUs
- AllGather GEMM
- GEMM ReduceScatter