A detailed GPU cache model based on reuse distance theory
摘要&结论¶
顺序处理器 Cache 建模理论:
- 基于Stack(Reuse) distance
Reuse distance
本文中出现的 Reuse distance 指两次访问间出现的 唯一 地址/ Cacheline 数量
问题:GPU 无法直接使用 Reuse distance 进行建模
- 并行执行
- 细粒度多线程
Reuse distance 扩展至 GPU:通过建模
- 线程层级调度: threads, wraps, threadblocks, sets of active threads
- in-flight 内存请求与条件/非均匀延迟
- Cache 联通性
- MSHRs(Miss-status holding-registers)
- wrap divergence 问题
in-flight 内存请求
已发送但尚未完成的内存请求
Wrap divergence
- 一般定义:一个 wrap 内的32个线程由于处于不同的控制流路径(如条件分支), 导致无法同时执行,从而串行化为分批执行,造成硬件资源空置
- 本文中,Wrap divergence 指的是由于不同 wrap 执行效率不同从而导致的 wrap 间的差异 (不同于 round-robin 的 wrap 调度)
引言¶
问题:GPU 片外内存带宽受限
- 解决:尽可能充分利用片上存储
GPU 片上存储的目的
GPU 片上存储是为了减少 off-chip memory traffic(性能瓶颈)
- 不是为了降低访问延迟:通过细粒度多任务实现访问延迟掩藏
- 应用:对于访存密集型程序,通过增加 Cache hit rate 来减少 off-chip memory traffic 从而获得性能提升
结论:GPU 程序优化关键在于 Cache 局部性优化
- 关键:考察 Cache miss 类型,预测 Cache miss 的源与数量
- 方法:建立 Cache model
- 应用:软件 (指导编译器、程序员参数选择);硬件 (加速 DSE)
3C 模型:Cache miss 分为 compulsory, capacity, conflict
- 定量分析:通过 memory access trace 获取 reuse distance
- compulsory: 地址不在栈内
- capacity: 地址在栈内深度 > Cache size
- 问题:未考虑 conflict miss, 给出 miss rate 下界
- 适用:顺序执行架构、多核CPU
GPU Cache model 遇到的挑战:细粒度多线程和并行导致难以确定 Cache 访问顺序
- Reuse distance 仅适用于顺序访问
贡献:
- 对 reuse distance 理论的5个扩展,使之适用于 GPU
- 通过 micro-benchmarking 发现2个架构细节: GPU set 映射, MSHRs 的个数
- 聚焦于 L1d$ 建模,L1$ 后访问顺序确定,可利用现有的多核 CPU 模型建模 L2$
背景¶
NVIDIA Fermi 架构执行模型¶
使用GTX470进行实验
并行架构:
- 16核(SM), 每核32 PE
CUDA / openCL 执行模型:
- kernel: 并行执行的程序
- threads / workitems: kernel 实例,处理不同数据
- threadblocks / work-groups: 一组 thread
- threadblocks 内部可进行同步、通信
- 一个 threadblock 被映射到一个 core, 一个 core 可管理8个 threadblock / 1536个 thread
- active threads: SM 内正在执行的 thread
- 以 warp / wavefront 为单位(GPU 调度以 warp 为单位)
- 1 warp ~ 32 threads, 以 lock-step 形式按 SIMD 在一个 SM 上执行
Cache 相关术语
Cache-line 代表位置, Cache-block 代表数据
S 代表 #set
Cache 架构:
- 64KB 可配置L1$ (16/48KB | 48/16KB Scratchpad + Cache)
- SM 内共享 L1$
- 16KB 4路组相连 128 cache-line, cache-line 大小 128B
- 768KB L2$
- 所有核共享 L2$
- L1$ 负责处理片外 load, L2$ 负责处理片外 store
- 本文仅考虑 L1$, 故只考虑 load
Cache 替换策略未知
Reuse distance 理论¶
Reuse distance 定义:
- 地址粒度:对同一地址的两次访问间出现的==唯一==地址数。第一次访问某地址时,reuse distance = \(\infty\)
- Cache-line 粒度:对同一 Cache-line 的两次访问间出现的唯一 Cache-line 数
应用:计算 hit / miss rate (以 Cache-line 为粒度)
- compulsory miss: \(P(d=\infty)\)
- capacity miss: \(P(d\geqslant n\land d\not=\infty)\)
适用条件
此处提出的 Reuse distance 仅适用于全联通 LRU Cache
Reuse distance 计算实例
Cache-line size = 4B, Cache-size = 2 Cache-line
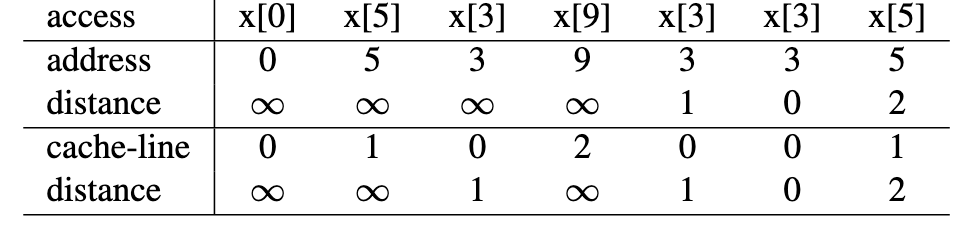
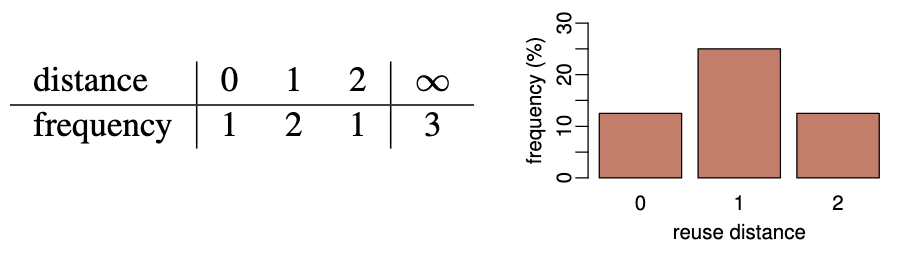
根据 LRU, x[9]替换x[5]
- compulsory miss = 3 / 8
- capacity miss = 1 / 8
模型¶
问题:Reuse distance 理论仅能用于顺序内存访问
- 需确定 GPU 的内存访问顺序
GPU 并行执行模型¶
问题:[[#NVIDIA Fermi 架构执行模型|执行模型]]决定线程在不同核上独立执行,但由于资源限制,并不是所有线程都能同时活跃
- 通过建模线程调度策略,对具体线程执行的具体指令定序,得到 instruction trace
执行模型:
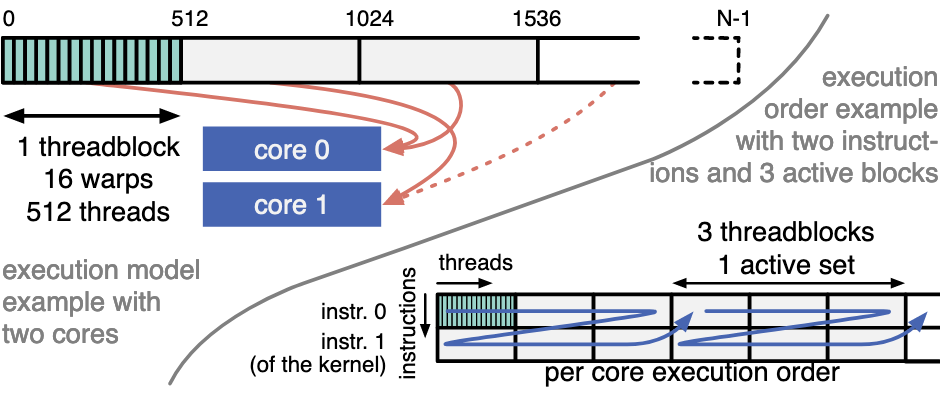
- 线程块分配:thread blocks 以 round-robin 方式分配给不同的 core, 直至占满整个 core
- 线程块调度:first-done, first-serve, 当一个 thread block 执行完,调度新的 thread block 参与执行
- 核内线程分组:根据硬件资源限制,核内线程分为多个 active set
- wrap 粒度调度:wrap 内的线程被同步调度
- wrap 间调度不直观,由后文提到的因素决定
执行模型示例
1 active set, 1 thread / wrap, 4 threads, 每个 thread 执行 2 loads(x[2*tid], x[2*tid+1]), 每个 cache-line 大小为4元素
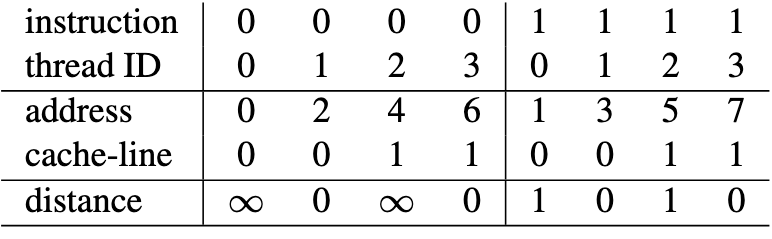
执行顺序:0-3号线程依次执行 inst 0, 再依次执行 inst 1
内存延迟¶
问题:GPU 内存延迟一般高于 CPU, Cache 无法瞬间响应请求(Cache 处理请求的顺序与不同核心的执行顺序不同)
- 通过建立时间戳,决定事件之间的相对顺序,建模 Cache 实际响应
固定访问延迟
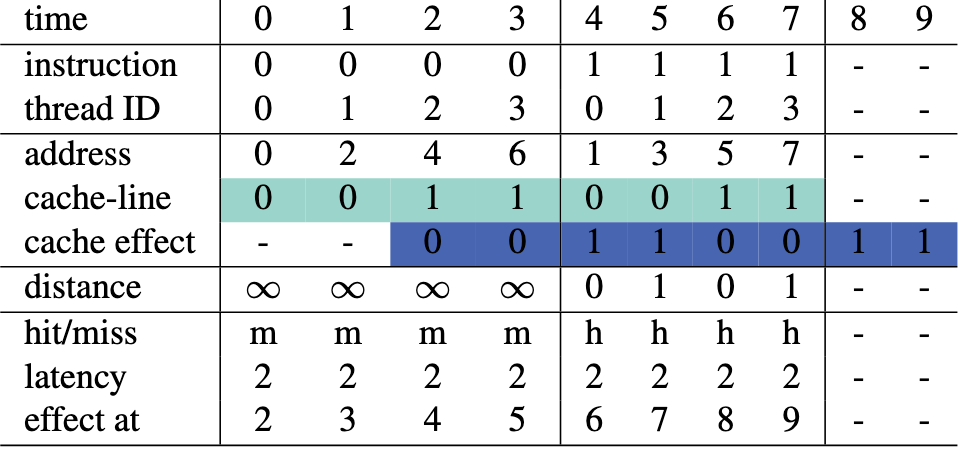
Reuse distance 计算:当前请求与实际 Cache line 请求之间的距离
- 对于 time = 2, 此时 thread 2 请求 Cache line 1, 而此前 Cache 并未处理过任何请求,distance = \(\infty\)
- 对于 time = 4, 此时 thread 0 请求 Cache line 0, 而 Cache 在 time = 3 时刚处理过 Cache line 0 的请求(由 time 1 发出),故 distance = 0
问题:引入非 compulsory miss 引起的 \(\infty\)
- 解决:引入 latency miss,即由于对该 Cache line 的前一次 miss 仍未处理完毕(in-flight),导致此次访问出现 miss
- 例如 time = 1 / 3, 在 time = 0 / 2 发出的 miss 请求由于未处理完毕,导致 time = 1 / 3 发生 latency miss
延迟类型扩展:
- 条件延迟:为 hit / miss 设置不同延迟时间
- hit / miss 由 reuse distance 和 Cache 大小确定
- hit latency: 流水线延迟 miss latency: 内存延迟
- 非规则延迟:使用半正太分布建模
- 模型:\(\lambda_{\min}+|\mathcal N(0,\sigma^2)|\)
- \(\lambda_{\min}\) 为最小延迟
- 为了得到内存访问顺序,而不是精确的延迟
- 模型:\(\lambda_{\min}+|\mathcal N(0,\sigma^2)|\)
条件延迟
hit latency = 0, miss latency = 2
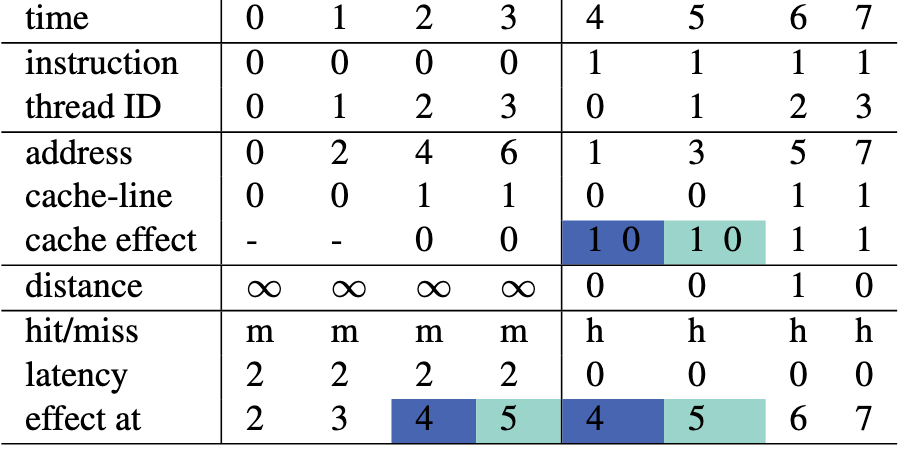
不同 cache effect 可同时发生:按照 issue 的顺序作用于 Cache
- 对于 time = 6, 认为在 time = 5 时,先访问 Cache line 1, 再访问 Cache line 0, 故 time = 6 时对 Cache line 1的请求,距离为1
修正:对于同一 Cache line 的 in-flight 访问,认为其同时起作用
- 对于 time = 1, 由于其与 time = 0 都访问 Cache line 0, 而此时 Cache line 0 的访问仍 in-flight, 故将其 effect at time 修正为 2
Cache 联通性¶
必要性:
- 对于顺序处理器,conflict miss 一般占比较少
- GPU 对 conflict miss 一般较为敏感
- GPU 访问模式较为固定
方法:将 Cache 中的每个 set 看作一个大小为 #way 的stack
问题:需知道内存地址到 set index 的映射
- 使用 micro-benchmark 确定
缺失状态保存寄存器 MSHR¶
目的:合并不同 wrap 对同一 Cache line 的请求
MSHR:
- 结构为一张表
- 每个表项记录请求的地址与同时请求的 warp 编号
- 当 MSHR 满后,无法处理内存请求
- 限制:请求的地址数限制;同时请求的 warp 数限制
- 处理:若一个 wrap 无法继续执行,将会被挂起
MSHR 示例
| Entry | Address | Type | Source | Pending Warps |
|---|---|---|---|---|
| 0 | 0xABCD | load | warp 3 | warp 3, warp 7 |
| 1 | 0x1234 | store | warp 1 | warp 1 |
| 2 | 0x5678 | load | warp 5 | warp 5, warp 9 |
MSHR 建模:当 MSHR 耗尽时,访问请求被取消,该线程被挂起
- 必要性:MSHR 个数的限制将改变线程执行顺序
MSHR 建模
1 个 MSHR, 2 个线程,分别为 thread 0 / 2
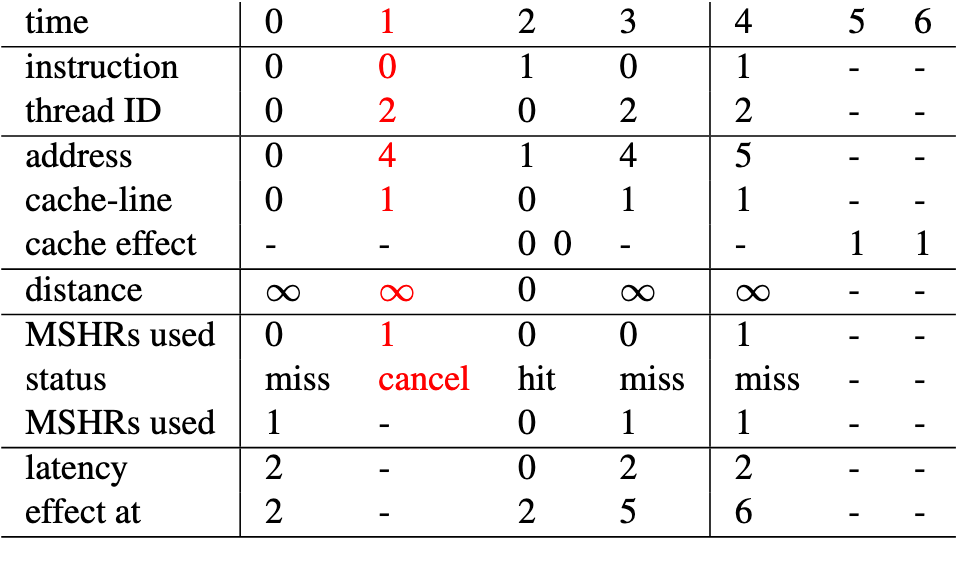
MSHR 限制:
- time = 1 时,MSHR 已耗尽,且指向 Cache line 0, 故访问请求被取消
- time = 4时,尽管 MSHR 耗尽,此时都指向 Cache line 1, 故访问请求被合并
问题:需知道 MSHR 个数
- 通过 micro-benchmark 确定
Warp 分歧¶
调度实现:使用 wrap queue 管理
- 初始时,wrap queue 被 active wrap 填满,按照 warp id (thread id \% wrap size) 排序
- 每次取出 wrap queue 队首 wrap, 执行内存请求
- 执行完毕后,根据 latency 插入到队列的相应位置
- 若由于 MSHR 用完而访问失败,移至队尾
模型实现¶
结构:
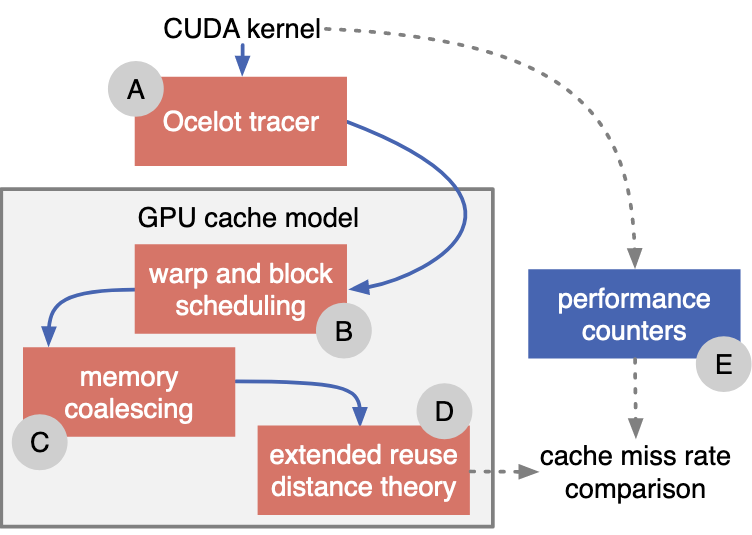
- 使用 Ocelot tracer 得到单个 thread 的内存访问顺序
- 通过调度决定内存访问顺序
- 对内存访问进行合并
- 压缩 memory trace
- 进行 reuse distance 分析
- 使用 Bennett - Kruskal 算法 \(\mathcal O(N\log(N))\)
- 结果验证
- 使用 NVPROF 验证 hit / miss rate
实验¶
Micro-benchmark¶
联通性¶
目的:寻找 address -> set index 映射方式
方法:起 128 线程,每组线程执行如下3个阶段的操作
- 访问连续 Cache line,将 Cache 填满
- 128 线程产生 16 个内存合并访问,填满 L1$ 的 16KB Cache 部分
- 访问部分地址
- 每次访问一个地址,扫描所有地址,确定映射关系
- 再次访问阶段1中访问的地址,通过观察响应时间确定 hit / miss, 从而判断阶段2中访问的地址导致哪些 Cache line 发生替换
__global__ void mb1(int* mem, int* time, int* sv) {
// Stage 1
for (i = 0; i < 32; i++)
temp = mem[tid+i*128]; // 128 threads
// Stage 2
if (tid == 0)
temp = mem[sv];
// Stage 3
for (i = 0; i < 32; i++) {
start = clock();
temp = mem[tid+i*128];
time[tid+i*128] = clock() - start;
}
}
映射:
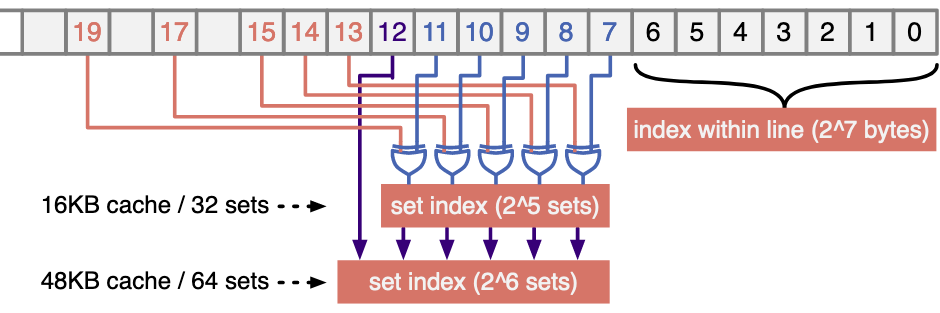
- 16KB Cache: 16K / (4 * 128B) = 32 sets, |index| = 5
- 48KB Cache: |index| = 6
验证:
- 16KB Cache, 32 set, 4 way, 128 Cache line
- Kernel: 含有两个相等的循环,以一定步长执行连续的 load 操作
- Miss rate 含义:
- 50%: 第一个循环 miss(冷启动), 第二个循环 hit
- 说明第一个循环中访问的元素被无重叠映射到不同 Cache set
- 100%: 第二个循环 miss
- 说明第一个循环中访问的元素中有被映射到相同 Cache set 的
- 50%: 第一个循环 miss(冷启动), 第二个循环 hit
-
与映射的关系:
- 元素可被映射的访问与参与映射的 bit 的数量有关
- 设 t 为在执行 load 操作时涉及到的 bit 中参与映射的 bit 数量,则可容纳的不同元素数量为 \(2^t\cdot 4\), 其中 4 为一个 Cache set 中含有的 Cache line 个数(way)
-
现象:
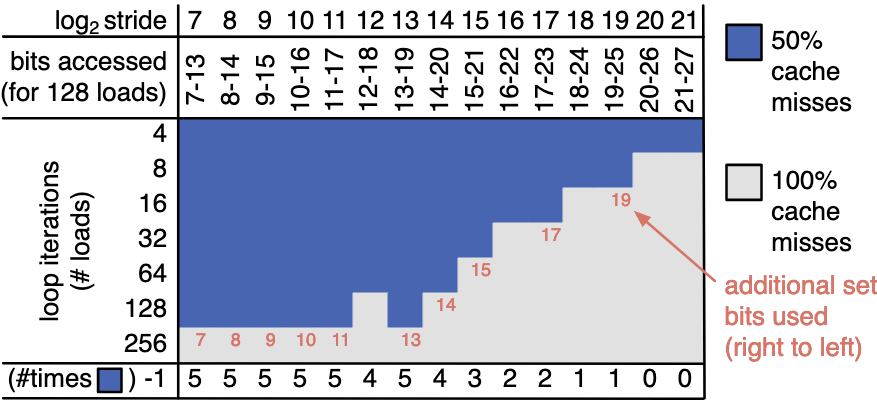
- 对于\(\log_2\text{stride}=7\), 每个循环执行 128 个 load 时,涉及到的 bit 有 7 - 13, 将 128 个元素 cache 住,说明 addr[13:7] 中有 5 个 bit 参与了映射
- 对于 256 load, 由于 Cache line 共 128 个,故一定发生 capacity miss
- 对于 4 load, 由于 way = 4, 都映射到一个 Cache line 也能存的下
MSHR¶
目的:确定每个核的 MSHR 个数
方法:跑 NUM_WARPS 个 warp, 每个 warp 跑一个线程,每个线程发 NUM_LOADS 个请求
- MSHR 会限制一次性发出的请求次数
- 一旦被限制,内存请求时间会显著变长(发生 stall)
__global__ void mb2(int* mem, int* time) {
if (tid % 32 == 0) { // launch 1 thread / warp
start = clock();
for (i = 0; i < NUM_LOADS; i++)
// 1st 32: 32 * 4 = 128, request different cache-line
// 2nd 32: 32 threads / warp
temp = mem[32*(tid + i*NUM_WARPS*32)];
time[tid/32] = clock() - start;
}
}
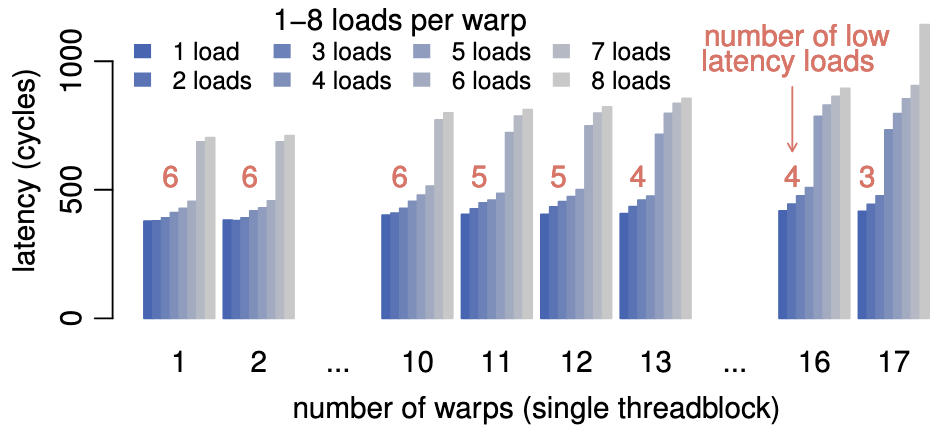 + 一个 warp 最多使用 6个 MSHR
+ 共 16 x 4 = 64 个 MSHR
+ MSHR 个数:允许同时执行的最大请求数
+ max(# warps x # loads) = 64
+ 一个 warp 最多使用 6个 MSHR
+ 共 16 x 4 = 64 个 MSHR
+ MSHR 个数:允许同时执行的最大请求数
+ max(# warps x # loads) = 64
模型验证¶
benchmark: PolyBench/GPU, Parboil
模型 VS 硬件计数器¶
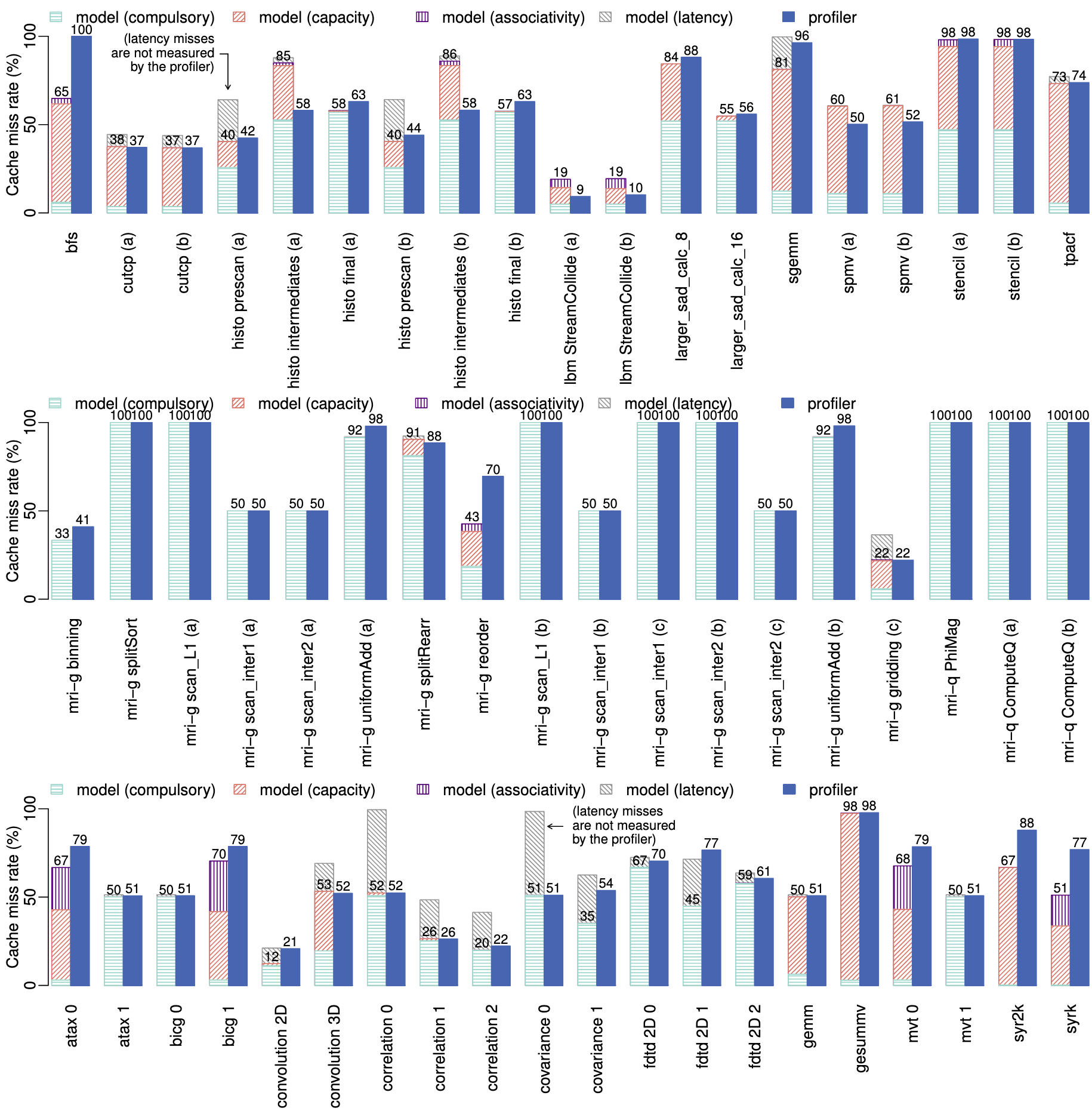 left bar: model, right bar: profiler
结论:
left bar: model, right bar: profiler
结论:
- 模型 compulsory miss <= 实际 miss
- compulsory miss 与 Cache 参数无关
- 大部分 Kernel 没有 associativity miss
- benchmark 中没有因 MSHR 限制而产生额外 miss
- 模型对 memory latency 极其敏感
- 需对 Cache 以外的部分进行建模以得到更为精确的延迟
总结:
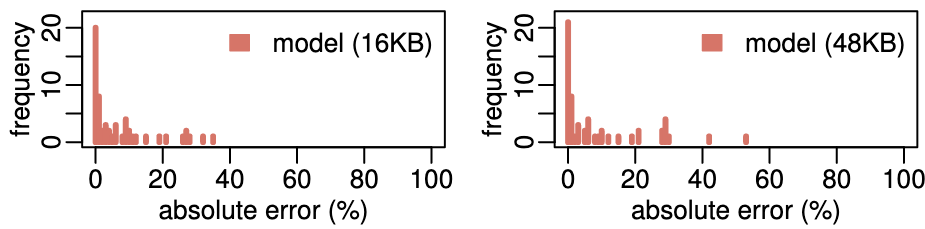
指标:绝对误差几何平均
消融实验:依次去除对不同硬件特性的建模,观察 miss rate 绝对误差几何平均的变化
模型 VS 模拟器¶
比较对象:GPGPU-Sim v3.2.0
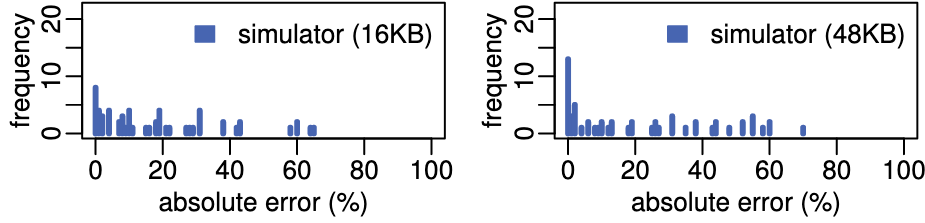
结论:
- 准确度更高
- 16KB: 模型误差 6.4%, GPGPU-Sim 误差 18.1%
- 64KB: 模型误差 8.3%, GPGPU-Sim 误差 21.4%
- 效率更高
- 268x 加速:对于 'cutcp', GPGPU-Sim 耗时 10h, 模型耗时 10s
应用:Cache 参数评估¶
参数:联通性, Cache size, Cache-line size, #MSHR
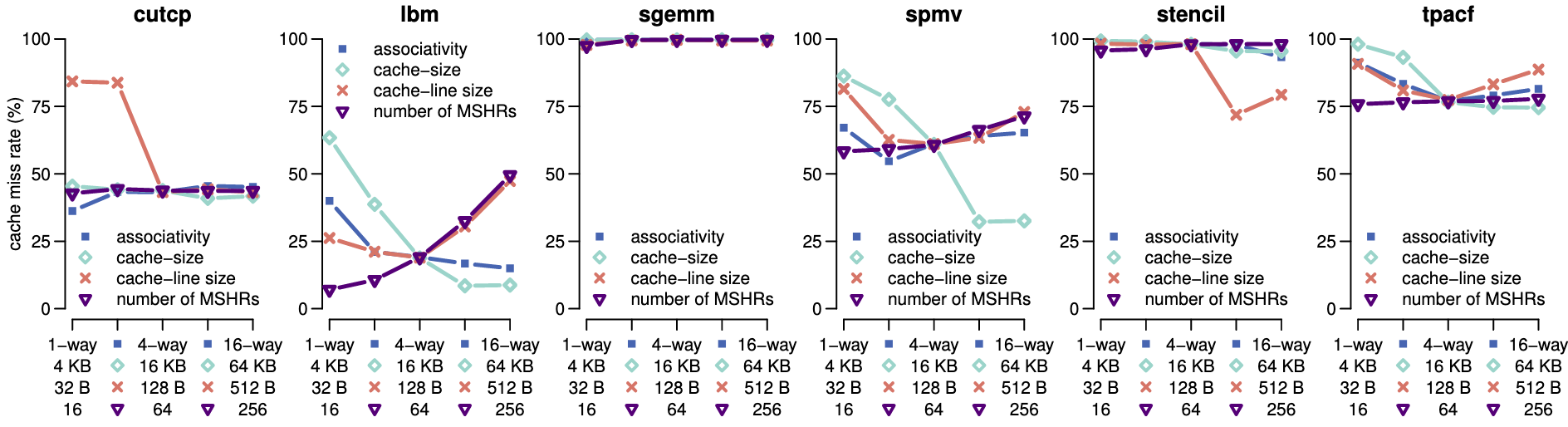
结论:
- 对于给定的 benchmark, 联通性影响小
- Cache-size 对 'lbm', 'spmv' 最关键
- Cache-line size 对 Cache miss 同时存在积极、消极影响
- 较少的 MSHR 能使得线程内的局部性被更好的发掘
- 调整执行顺序后,跑在前面的线程可以避免被其它线程替换数据