2023全球智能汽车挑战赛日志¶
Day0 23/11/10¶
事项¶
- 赛事报名
- 数据资源下载
- 提交baseline
收获¶
-
明确赛题任务:生成视频对应的内容分析
-
环境配置:由于paddle结构较为混乱,按照如下方式安装
- 了解飞桨平台使用方法
Day1 23/11/17¶
事项¶
收获¶
- CLIP模型:
-
动机:
- 使用自然语言中的监督信号
- 迁移性强的模型
-
原理:
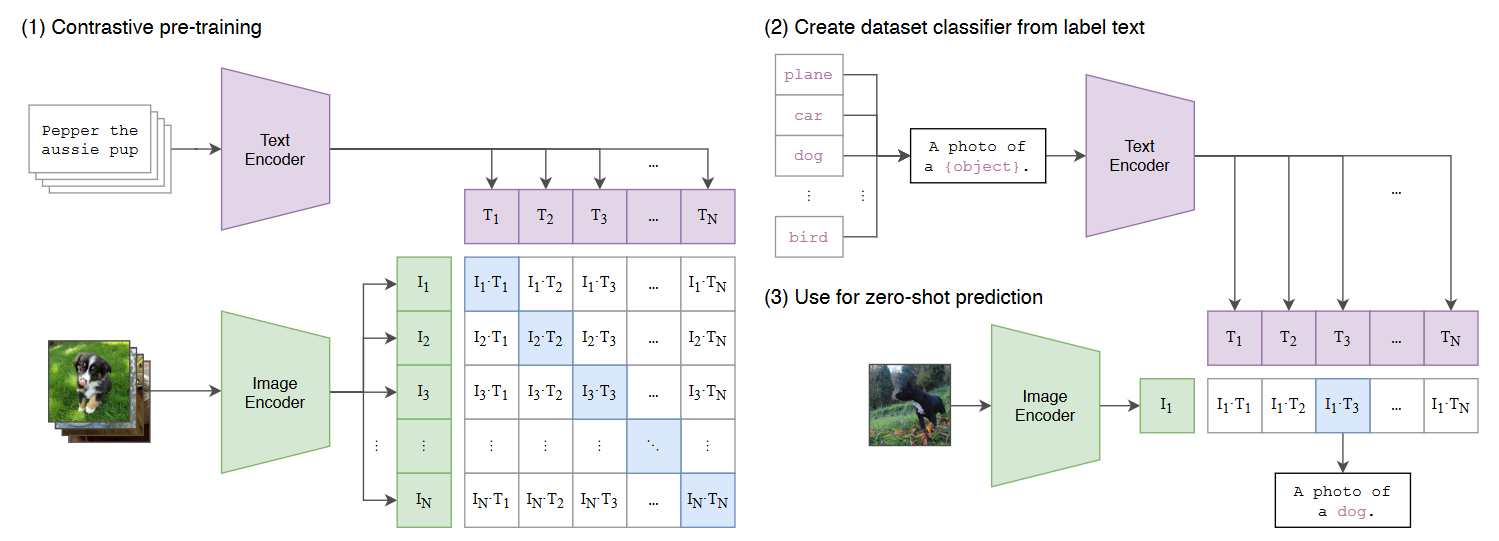
架构:图像编码器,文本编码器
训练:
- 数据类型:
(Image, text),即图像与其对应的描述文本 - 对于大小为\(N\)的batch,对应的图像文本对为正样本,共\(N\)个;非对应的为负样本,共\(N^2-N\)个
- 采用对比学习手段进行训练
模型参数量大,使用对比学习手段降低计算量
预测:
- 利用提示词模板,将类别嵌入形成描述性语句
训练数据采取描述性文本,此处应根据类别构造提示文本形成语句
- 利用图像编码器与文本编码器提取特征
- 分别计算图像特征与各文本特征的余弦相似性,取相似性最高的作为预测结果
- 数据类型:
-
结论:
- 图像、文本模型的复杂程度与模型性能呈正相关
- 使用大数据集(4亿图像文本对)训练模型得到较好效果
- 使用描述性文本而非标签可减小标签收集难度
- 模型具有较强zero-shot推理能力,通过固定模型本体训练分类头的方式微调,few-shot效果甚至不如zero-shot
-
局限性:
- 迁移性强,而非针对每个具体领域性能都强
- 存在分布偏移问题,在MNIST上的效果奇差
- baseline解读:
baseline使用百度飞桨提供的clip模型,从视频中抽帧进行识别
clip_id = video_path.split('/')[-1]
cap = cv2.VideoCapture(video_path)
img = cap.read()[1]
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
image = transforms(image).unsqueeze(0)
由于clip模型并非能胜任所有检测任务,故仅利用clip做天气与道路结构识别的任务
Day2 23/11/19¶
事项¶
- 第一次提交
- 更换CLIP模型
- 尝试提示词工程
收获¶
- 将CLIP模型更换至openai-clip使用最大图像Transformer训练的模型,使用pytorch库进行推理,baseline修改如下
import torch
import clip
from PIL import Image
import cv2
import glob
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-L/14@336px", device=device)
paths = glob.glob('../../Dataset/Tianchi2023/初赛测试视频/*')
paths.sort()
video_path = paths[0]
clip_id = video_path.split('\\')[-1]
cap = cv2.VideoCapture(video_path)
img = cap.read()[1]
image = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
image = preprocess(image).unsqueeze(0).to(device)
text = clip.tokenize(["clear","cloudy","raining","foggy","snowy"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
注:
cap.read()[0]会引发报错,故取cap.read()[1]作为第一帧- 使用最大的模型ViT-L/14@336px
- 使用GPU加速
- 由于需要将类别嵌入句子,构造如下提示词模板:
en_prompt = {
"scerario": [f"It's a photo of {_}" for _ in en_match_words["scerario"]],
"weather": [f"It's a {_} day" for _ in en_match_words["weather"]],
"period": [f"It's {_} now" for _ in en_match_words["period"]],
"road_structure": [f"The road structure is {_}" for _ in en_match_words["road_structure"]],
"general_obstacle": [f"{_} is in the road" for _ in en_match_words["general_obstacle"]],
"abnormal_condition": [f"{_} is happening" for _ in en_match_words["abnormal_condition"]],
"ego_car_behavior": [f"The car in the photo is {_}" for _ in en_match_words["ego_car_behavior"]],
"closest_participants_type": [f"The participant is {_}" for _ in en_match_words["closest_participants_type"]],
"closest_participants_behavior": [f"The participant is {_}" for _ in en_match_words["closest_participants_behavior"]]
}
- 对于模型返回Unknow的处理:设定阈值,当模型预测最大概率与最小概率差小于阈值时,认为结果未知
threshold = 0.1
if np.max(probs[0]) - np.min(probs[0]) > threshold:
single_video_result[keyword] = texts[probs[0].argsort()[::-1][0]]
else:
single_video_result[keyword] = "unknown"
- 改进方向:由于预测手段为抽帧静态分析,故无法完成动态特征检测,需利用不同模型完成不同任务
第一次提交¶

注:由于主办方提供的检测程序中场景一词错误的拼写为scerario,私自更正将会导致提交时报错
注意到利用阈值判断unknown导致大量特征变为unknown,利用先验为预测结果赋初值:
single_video_result = {
"clip_id": clip_id,
"scerario": "city street",
"weather": "clear",
"period": "daytime",
"road_structure": "normal",
"general_obstacle": "nothing",
"abnormal_condition": "nothing",
"ego_car_behavior": "go straight",
"closest_participants_type": "passenger car",
"closest_participants_behavior": "braking"
}
同时,由于部分路况仅在视频的某些部分出现,其出现概率中间帧大于起始帧,故取中间帧进行分析
将分数提升至134分
