2023雪浪算力开发者大赛日志¶
Day0 23/1/17¶
事项¶
- 队伍组建
- 赛题解读
- 数据资源下载
收获¶
- baseline:参照物,可供学习的现成代码
- 时下流行模型:lightGBM
Day1 23/1/18¶
事项¶
收获¶
-
Anaconda:包管理器,可为PyCharm提供环境;启动较慢
-
pandas:数据处理包
-
Jupyter:类似IDLE,支持图表显示,Markdown
-
工作重心在特征提取上(重点),主要通过数据处理手段,最后选择合适模型进行训练
-
baseline结构:
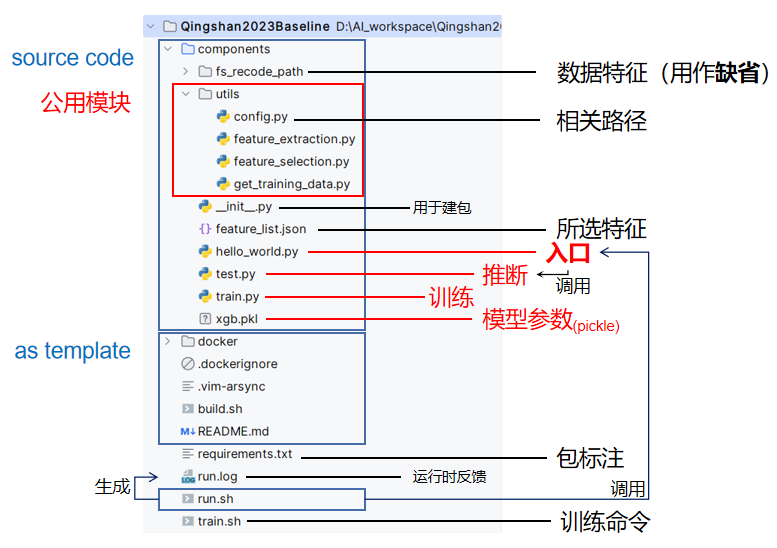
- 配置pycharm识别自定义模块:右键文件夹标记为源代码根目录
Day2 23/1/19¶
事项¶
- 了解基本解题流程
收获¶
- 基本流程:
graph LR
A[特征抽取]-->B[特征筛选]-->C[模型选择]-->D[代码测试]Day3 23/1/26¶
事项¶
- 初步探索赛题数据
- 逐行分析官方baseline训练过程
收获¶
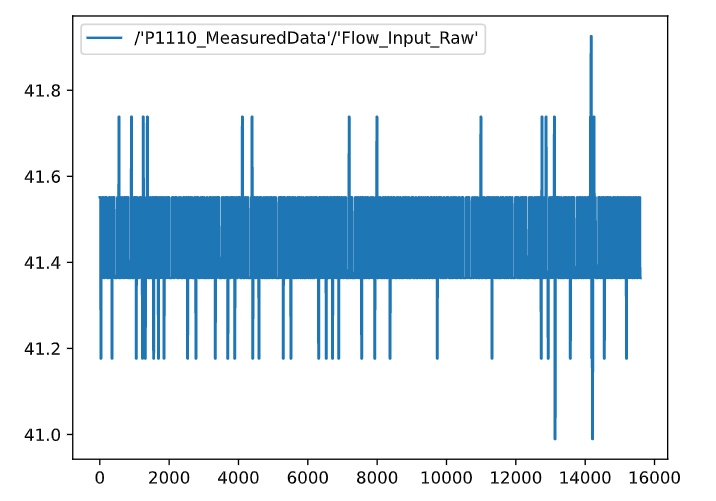
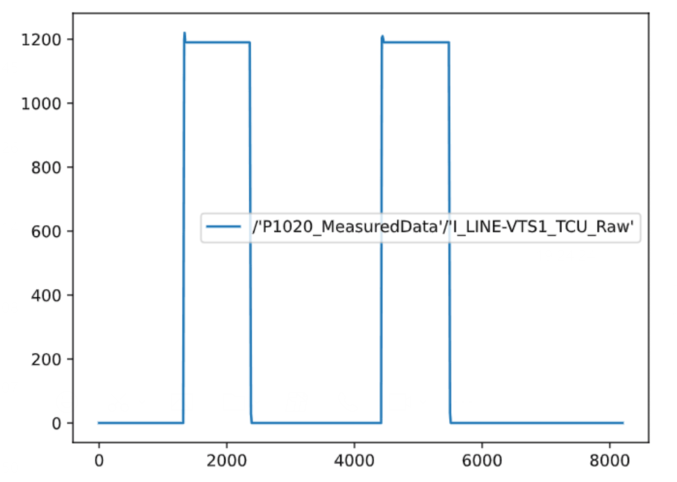
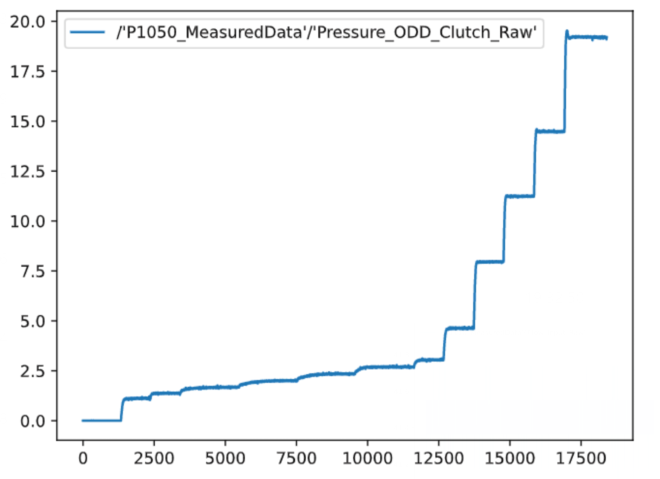
- 重复采样数据走势:
-
平均型
-
周期型
-
阶梯型
- 同传感器不同样本采样:
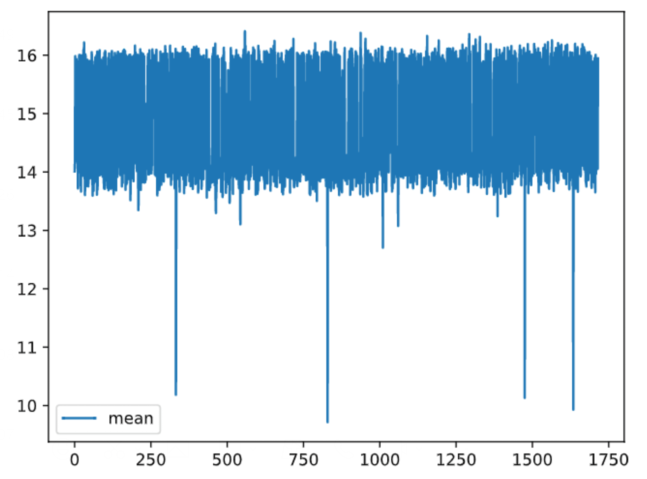
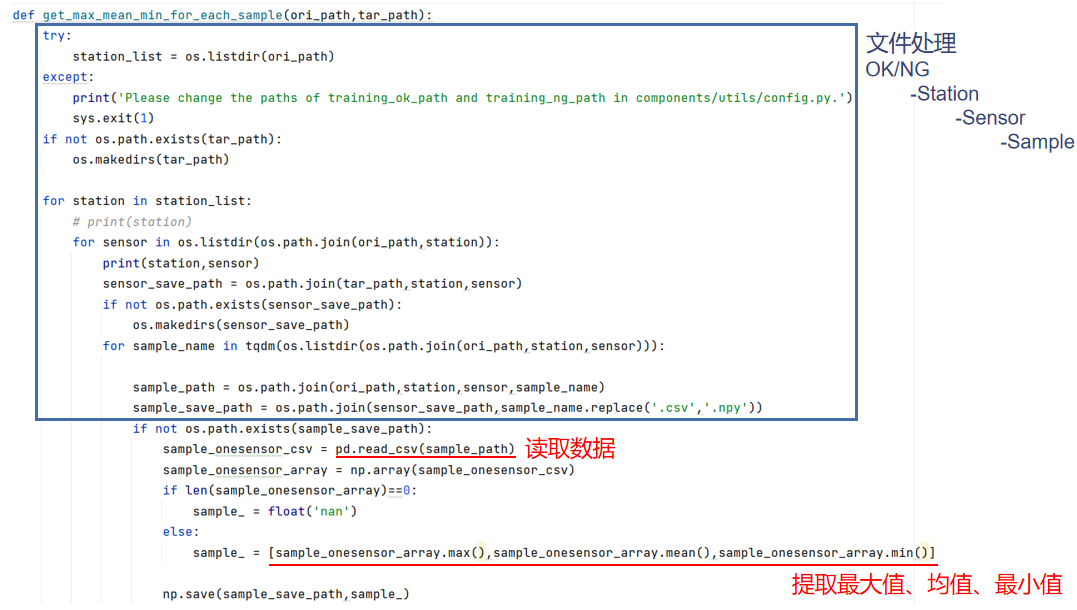
- baseline分析:
-
feature_extraction()
-
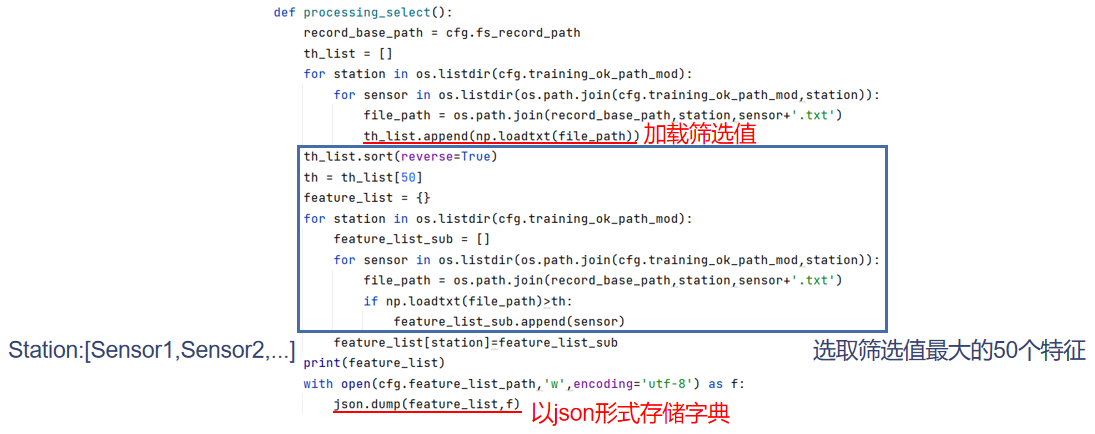
processing_record()

-
processing_select()
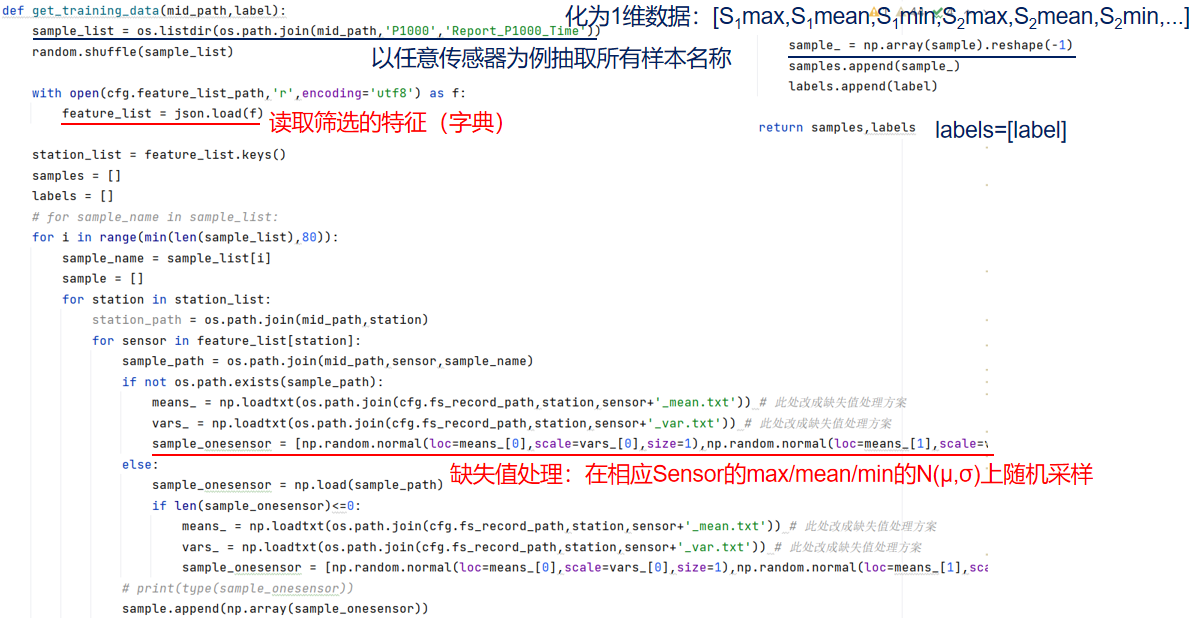
-
get_training_data()
-
train.py
Day4 23/1/27¶
事项¶
- 重构baseline
- 回归分析,傅里叶分析
收获¶
- 更新命名规则:
处理流程:
graph LR
A[Raw]--extract-->B[Pre]
B--extract-->C[Out]
B--selection-->D[features_list]命名规则:
-
文件路径
目录 内容 _C.raw_ok_path 原始OK数据路径 _C.raw_ng_path 原始NG数据路径 _C.pre_ok_path 预处理OK数据路径 _C.pre_ng_path 预处理NG数据路径 _C.out_ok_path 用于缺省数据路径 -
变量名
- 回归分析:
结论:不可行
- 傅里叶分析:
结论:难以提取主要频率、特征频率,不可行
初版方案:min,mean,max,var
- 路径字符串中"./"代表同级目录,"../"代表上一级目录
Day5 23/1/28¶
事项¶
- 提出初版训练方案
- 首次进行训练尝试
收获¶
- 训练方案:
方案选择——lightgbm.feature_importance
模型选择——lightgbm
缺省值方案——同均值同方差正太采样
- 数据处理第二版方案:
-
尝试对噪声建模:
齿轮模型:将零件抽象为两个咬合的齿轮,当齿轮表面光滑时,将平稳转动,稳定在平均水平;倘若齿轮表面出现粗糙,则会出现较大震动;齿轮较大时,发生周期较长,常规情况下成周期性发生较大偏移。
将表面粗糙定义为瑕疵,当整体瑕疵总数超过阈值时可视为“坏零件”。瑕疵表现为偏离常态的震动,反映为离群点。
-
方案:对所有离群点求和,并归一化
解释:\(\int df_{震动}\triangleq F_{瑕疵}\),对不同瑕疵对等的叠加,进行归一化操作。由于常规检测注重范围判断,故学习min,mean,max可学到数据的合理阈值,但无法对抗漏检陷阱;尝试撇去正常部分,对噪声进行学习。
- 模型训练细节:
-
float('nan')型数据的判断:
-
np.array.reshape报错及其处理:
当np.array中存在shape不一的数据时,执行该操作将引发错误
解决方案:放入np.array前先整形
-
保存到文件数据的整齐化:
当直接调用np.savetxt()时,无法保证再次读取的稳定性。加一个[]进行限制避免数据脏化
-
lightgbm对numpy型输入数据的要求:
当数据类型为list[np.array()]时将引发lightgbm报错(误认为2d-array而读取list[0].shape[1]造成越界)
解决方案:将其转化为2d-array
-
lightgbm数据划分:
先用sklearn.model_selection.train_test_split,再用lgb.Dataset
-
lightgbm基本调参:
-
lightgbm求f1参数:
由于lightgbm模型直接给出二分类概率,故需按照0.5为分界进行转化
Day6 23/1/29¶
事项¶
- 完成特征筛选部分
- 进行第一版提交
收获¶
- K折交叉验证筛选最优参数:
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5, shuffle=True, random_state=random_state) # 创建KFold对象
fold = 0
for train_idx, val_idx in kfold.split(samples): # 得到划分下标
train_X = samples[train_idx] # np.array花式下标:[list]
train_y = labels[train_idx]
test_X = samples[val_idx]
test_y = labels[val_idx]
train_dataset = lgb.Dataset(train_X, label = train_y)
val_dataset = lgb.Dataset(test_X, label = test_y)
# ...
feature_importance[f'fold_{fold + 1}'] = model.feature_importance() # 创建新列
fold += 1
feature_importance['average'] = feature_importance[[f'fold_{i}' for i in range(1, n_splits + 1)]].mean(axis = 1)
feature_importance_sorted = feature_importance.sort_values(by = 'average',ascending=False)
- pandas与numpy的关系:
pandas:用于数据读取、裁剪、编辑(类似于excel表格)
numpy:用于数据运算(类似于计算器)
- 单测试数据的细节:
lgb模型接受二维数据,当输入唯一时,传入形状应为[[样本数据]]
Day7 23/1/30¶
事项¶
- 修改第一版提交中的问题
- 配置Docker环境
收获¶
- 第一版提交返回结果:

问题及其解决方案:
| 问题 | 解决方案 |
|---|---|
| pip报错:找不到对应的包 | 1.换pip源:修改Dockerfile |
| 2.修改requirements.txt:取消包版本限制(pandas与算盘本地的发生冲突/清华源无最新numpy) | |
| 3.无法安装最新的包:修改Dockerfile中python版本要求 | |
| 运行时报错:找不到路径 | 修改inference()中data路径:将'.'去掉 |
- Docker环境配置:
系统要求:linux
安装方法:
首次运行将报错,根据提示信息安装curl。下载安装时间较长(约30min),成功标志:
If you would like to use Docker as a non-root user, you should now consider adding your user to the "docker" group with something like:
Remember that you will have to log out and back in for this to take effect!
WARNING : Adding a user to the "docker" group will grant the ability to run containers which can be used to obtain root privileges on thedocker host.
Refer to https://docs.docker.com/engine/security/security/#docker-daemon-attack-surface for more information.
- Docker基本使用:
build完成后在当前目录下并不出现任何文件,使用
查看构建完成的镜像名称,并利用命令
运行容器。
注:
- 挂载目录后,将被映射为容器内的同名文件,可当做当前目录下的文件进行使用
- 容器内的输出文件需利用指令进行查看
-
每次修改源代码,需重新执行build操作
-
pycharm打开终端后显示报错信息的解决方案:
管理员身份打开powershell,执行
并选择Y.
第一次提交¶
第一版运行结果:

官方Baseline运行结果:

与官方Baseline相比,第一版模型使用到了方差、lightgbm与select_by_gbm等技术,推测如下:
- 方差是一个重要特征,这与齿轮模型相吻合
- lightgbm优于xgboost
- select_by_gbm与lightgbm契合度更高
而选择了max,min,mean,std,25%,75%、lightgbm+select_by_gbm+方差筛选的版本得分为零,结合模型筛选前后f1变化(1600+特征f1为63%,200特征f1为87%),推测:模型泛化能力与所选择的特征数量不一定成正相关。
Day8 23/1/31¶
事项¶
-
具体化“齿轮模型”,新增离群方差指标var_iso
-
新一轮数据提取:max,mean,min,var,var_iso
-
提出特征筛选新方案:
处于对特征数量控制的考量,将特征分为两类:必要特征+赠送特征。必要特征即为lightgbm选择的最重要的50个特征,赠送特征即为同传感器的其它衍生数据。对于赠送特征,进行额外的方差筛选,以减少最终的特征总量。
收获¶
- 离群方差指标:
原理:采样噪声是对部件瑕疵的反映,反映在数据上是离群点的形式。通过对离群点的处理,在齿轮模型中可以反映部件对检测项目的瑕疵程度
数学表达:
-
离群点定义:
Tukey's test:定义四分位距IQR,并在IQR基础上定义离群点集\(X_{ISO}\) $$ IQR\triangleq X_{75\%}-X_{25\%}\ X_{ISO}\triangleq {x\in X:x\notin[X_{25\%}-1.5IQR,X_{75\%}+1.5IQR]} $$
-
离群点处理:
为了解决不同数据类型在数据范围上的差异,先对数据进行z-score标准化,化为\(\mu=0,\sigma=1\)的标准形式,再进行离群点提取,最后计算离群方差指标\(var_{ISO}\),下为原始定义:
-
原始定义的修正:
注意到如下数据(右为正样本,左为负样本):
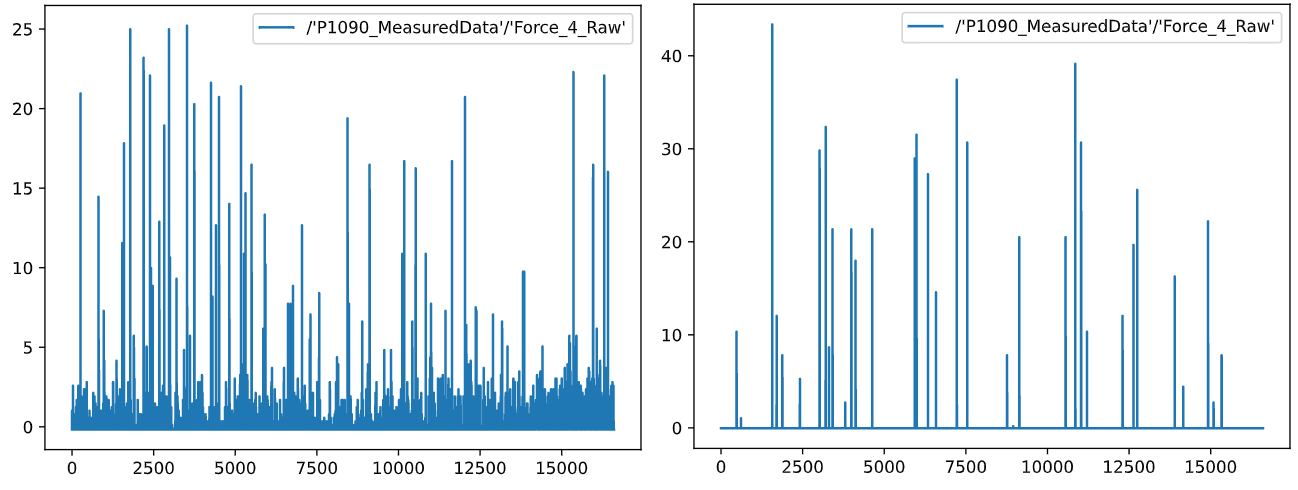
根据对齿轮模型的常识理解进行判断,明显正样本的瑕疵程度小于负样本,而负样本var_iso远远小于正样本var_iso。推测问题如下:
- 正样本在瑕疵数量上占优,负样本在瑕疵大小上占优
- 原定义计算的方差,衡量的是瑕疵大小程度,故正样本在var_iso衡量下不及负样本
基于上述问题,做出以下修正:
-
修改定义为: $$ var_{ISO}=\sum_{x\in X_{ISO}}|x| $$ 一方面,使得瑕疵点多的样本取得的数值更大;另一方面,减弱瑕疵大小在衡量瑕疵时的重要程度
-
调整负样本的归一化方式:
当负样本整体发生偏移时,此时\(\mu{-}\)难以正确表达基准点,经z-score后将无法充分计算瑕疵。为此,使用该传感器下所有正样本数据均值的均值\(\overline{\mu +}\)来标准化负样本。
最终提取方案如下:
- 先对正样本进行数据提取与二次提取
- 利用正样本的二次提取数据对负样本进行提取
- 提取过程中增加新指标的计算,计算步骤:z-score标准化——tukey's test离群点提取——带入修正定义进行计算
Day9 23/2/1¶
事项¶
- 完成第二版模型的训练
- 进行第二版提交
收获¶
- 第二版特征筛选方案:
graph LR
A[所有特征]--第一次方差筛选:0.5-->B[预筛选特征]
B--lgb筛选-->C[核心特征]
C--同传感器扩张-->D[扩展特征]
D--第二次方差筛选:0.1-->E[最终特征]解释:
- 由于将2000+特征直接喂给lgb进行筛选效果较差,故先用方差筛选筛去一部分较水的数据,提高核心数据浓度
- 同传感器扩张将充分利用比赛规则,容纳更多的特征
- 为了进一步提高有效特征的浓度,故进行第二次方差筛选筛去扩张中得到的水特征
实现:
-
修改特征存储方式:
以特征为最小数据单元
- 第二版训练方案调整:
由于按正常手段训练发生模型auc迅速达1的异常现象,对训练集测试集比例进行一定的调整,以提高测试集上f1score的值(明显存在过拟合隐患)
- 第二版提交结果:

Day10 23/2/2¶
事项¶
- 修正第二版提交
- 学习git分支切换操作
收获¶
- 第二版提交问题:

问题及其解决方案:
| 问题 | 解决方案 |
|---|---|
| 路径错误,可能由路径中的空格/中文导致 | 1.删除对该特征的选择 |
| 2.重新训练该模型 | |
| numpy报Warning:invalid value encountered in subtract,由样本数据中的整数与\(\overline{\mu+}\)相减导致 | 强制类型转换 |
- git分支:
假设当前在master分支下进行了3次提交,并建立dev分支,如图:
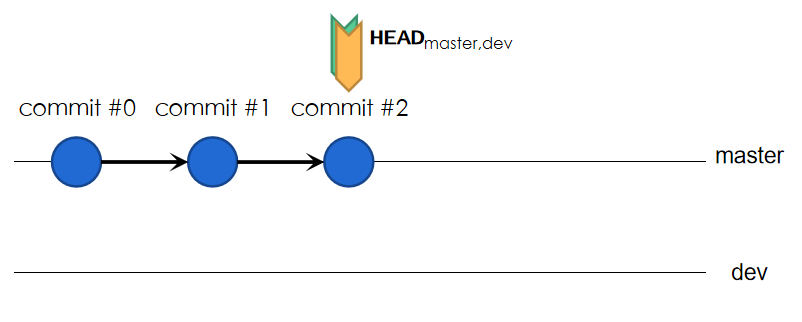
HEAD指向当前处于的位置,与工作区相同步。而此时master分支与dev分支可以理解为commit#0-#1-#2(从右向左构成完整的链,dev当前并不为空),而master,dev分支各自指向末次提交。
现向dev分支进行一次提交,结果如图:
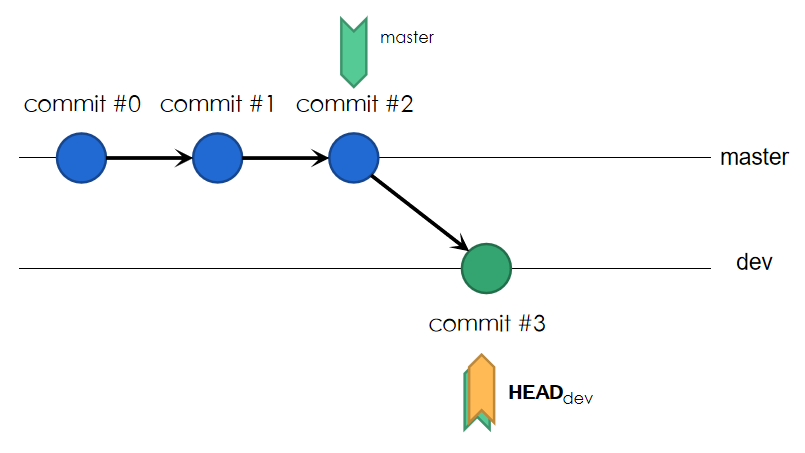
master分支末尾不变,dev分支末尾随提交而变化,HEAD移向dev分支末尾。此时head分支为commit#0-#1-#2,而dev分支为commit#0-#1-#2-#3,工作区与HEAD指向同步。
若想让工作区回到master末尾的状态,应执行签出(check out)操作,结果如下:
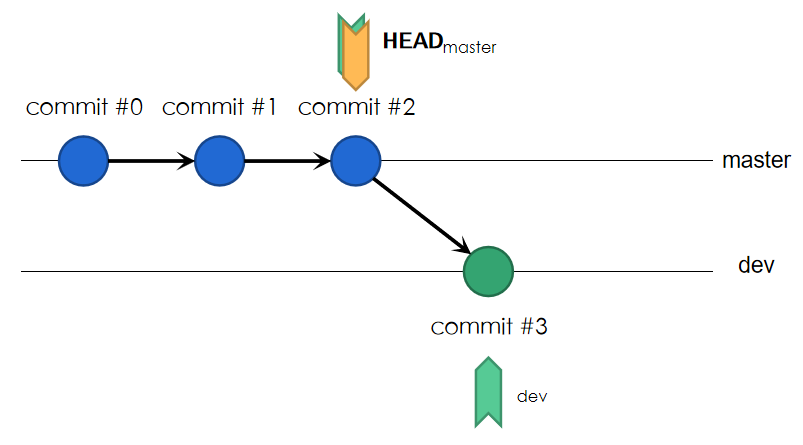
签出后,工作区代码同步变化,再次进行签出操作即可回到dev分支处。
第二次提交¶
第二版运行结果:

与第一版相比,此次引入了var_iso,得分并不理想,加之模型训练困难,推测如下:
- “齿轮模型”有效性值得商榷
- var_iso难以被lightgbm所掌握,容易引发拟合错误
- 模型预测能力与有效特征浓度成正相关
- 模型预测能力的好坏可从训练进程中进行推断
仍需寻找符合数据“自然形态”的特征。